SageMakerでTensorFlow+Kerasによる独自モデルをトレーニングする方法 TL;DR AWS SageMakerにおいて、TensorFlow+Kerasで作成した独自モデルをScript Modeのトレーニングジョブとして実行します。 トレーニングジョブ用のDockerイメージについてはSageMakerが提供するイメージをそのまま利用します。このため、独自のイメージをビルドする必要はありません。

Auto-KerasでTextClassifierを使って見る TL;DR Auto-KerasでTextClassifierを使って見ました。 Auto-Kerasを利用した画像分類(ImageClassifier)については、Auto-Kerasを使って見るを参照してください。
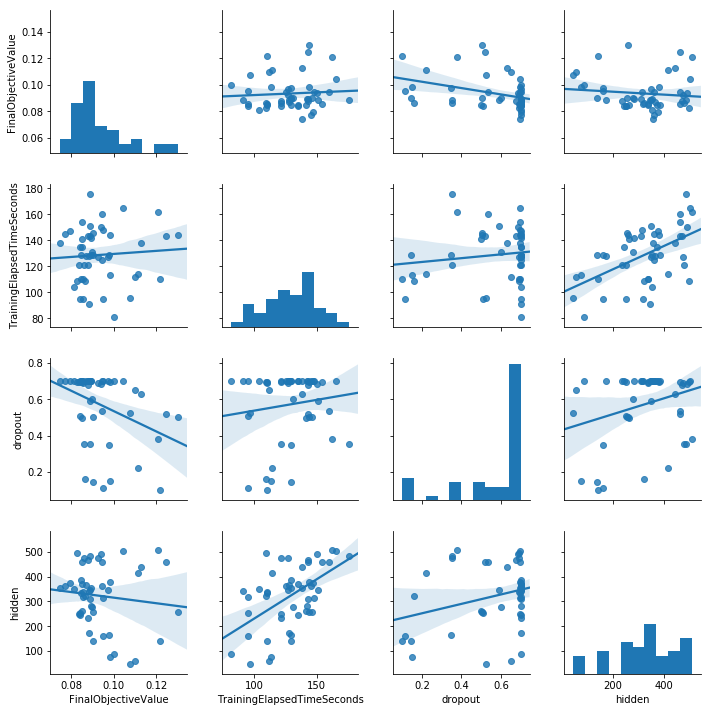
Auto-Kerasのバージョンは0.3.5です。

Auto-Kerasを使って見る TL;DR AutoML実装の一つであるAuto-Kerasを使ってみました。 Auto-Kerasのインストールから、チュートリアルにあるMNISTの分類モデルの作成までです。
AutoMLとは AutoML(Automated Machine Learning)は、機械学習プロセスの自動化を目的とした技術のことです。 以下のQiitaの記事がとてもわかりやすいです。
各種Tokenize手法に依存したベクトル化手法の比較 TL;DR 以下のベクトル化手法を比較しました。
wikipedia2vec sentencepieces + word2vec char2vec ベクトル化するための学習データとして日本語Wikipediaを使用しました。
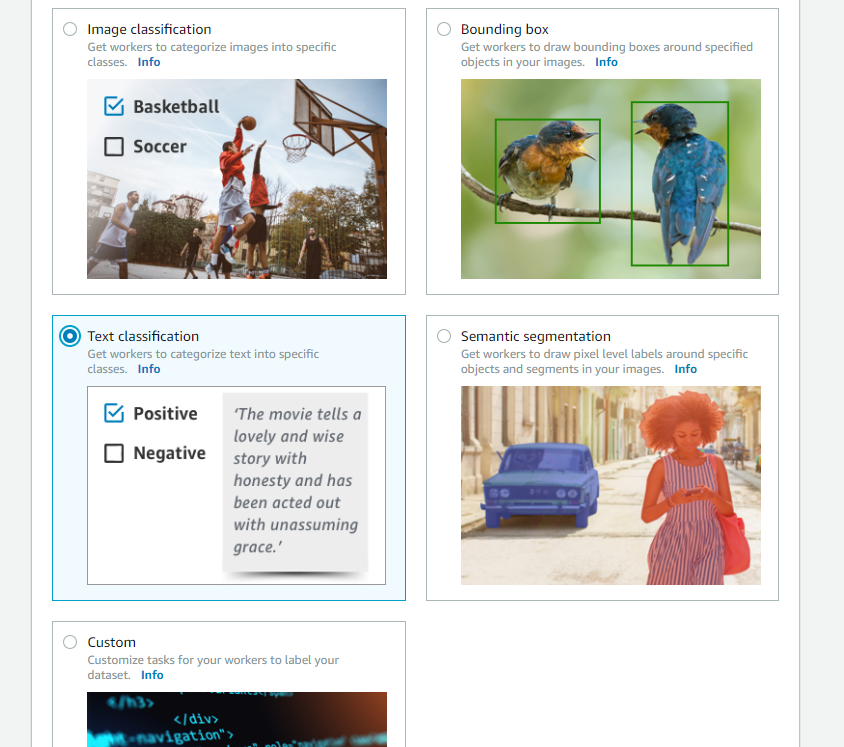
AWS SageMaker Ground Truthでテキストのラベリングを試してみる TL;DR AWS SageMaker Ground Truthは、機械学習用のラベルデータ作成を行うためのプラットフォームです。 SageMaker Ground Truthでは、以下の種類のラベルデータを作成することができます。

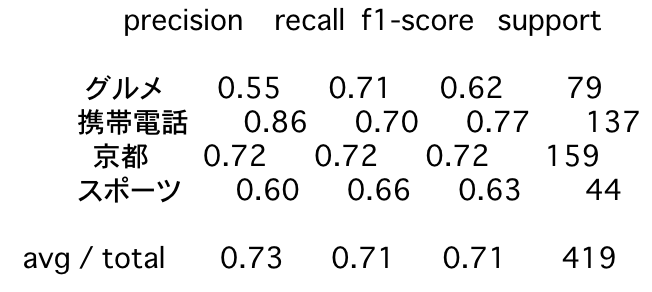
AIGAOMOI - 日本語文書感情分析サービス 概要 文章を機械学習で分析し、良い感情(Positive)であるか、悪い感情(Negative)であるかを分析するWebサービスです。 サーバレス、SPA、機械学習関連APIのデモンストレーションとして作成しました。
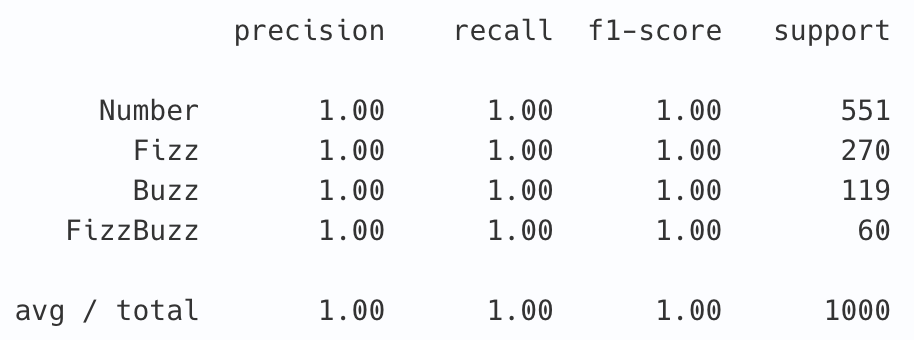
FizzBuzz問題をニューラルネットワークで解いてみる TL;DR FizzBuzz問題をニューラルネットワークで解いてみます。
ラベルデータの作成 import pandas as pd results = [] for i in range(1, 10000 + 1): if i % 3 == 0 and i % 5 == 0: results.append((i, 'FizzBuzz')) elif i % 3 == 0: results.append((i, 'Fizz')) elif i % 5 == 0: results.append((i, 'Buzz')) else: results.append((i, 'Number')) data_df = pd.DataFrame(results, columns=['Number', 'Results']) display(data_df.head(15))

GANでピカチュウを描いてみる TL;DR GAN(Generative Adversarial Network)でピカチュウを描いてみるというネタです。
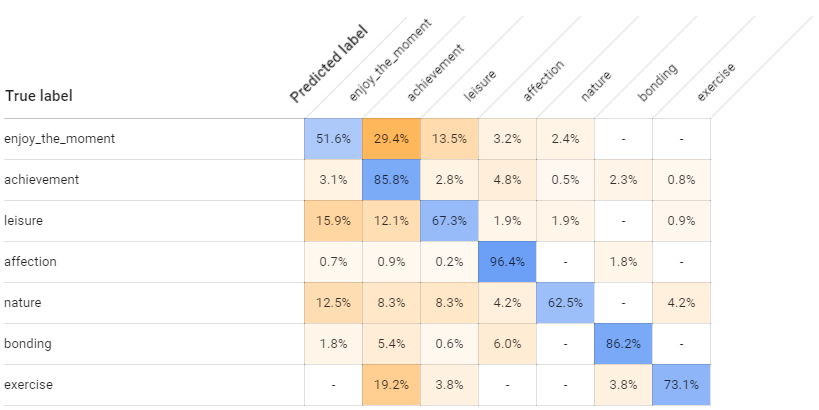
GCP AutoML Natural Languageのベンチマーク TL;DR デモデータを利用してAutoML Natural Languageと自作モデルの性能を比較してみました。 もう全部AutoML Natural Languageでいいんじゃないかなぁ・・・。
