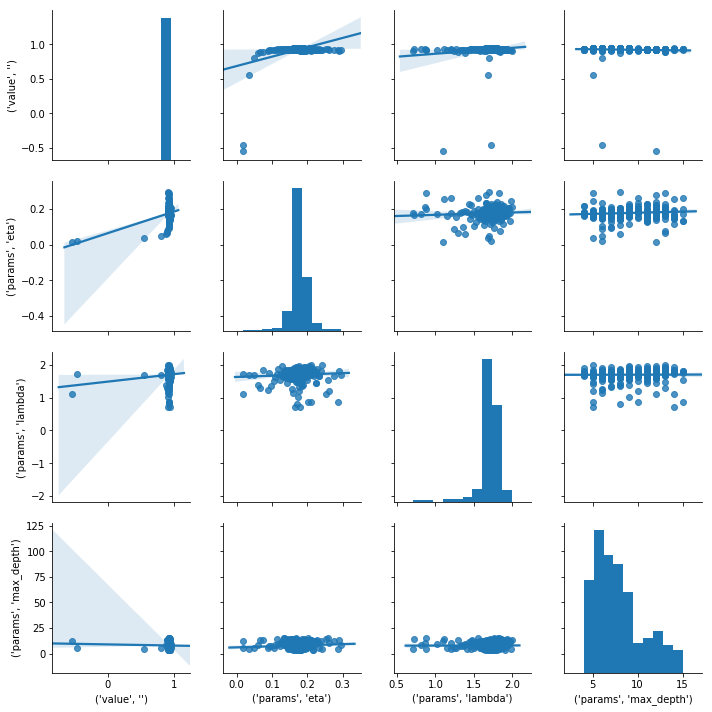
XGBoostをOptunaでパラメータチューニングする TL;DR XGBoostのパラメータをOptunaでチューニングします。 ベンチマーク用データとしてはボストン住宅価格データセットを使用します。
データ準備 scikit-learnのdatasetsを使ってデータをロードします。 学習データとテストデータの分割は8:2です。
もっと簡単に Keras BERT でファインチューニングしてみる TL;DR text-vectorianをバージョンアップし、BERT のファインチューニングで役に立つ機能を追加しました。

SageMakerでKerasの独自モデルをトレーニングしてデプロイするまで(Python3対応) TL;DR AWS SageMakerにおいて、Kerasによる独自モデルをトレーニングし、SageMakerのエンドポイントとしてデプロイします。 また、形態素解析やベクトル化のような前処理を、個別にDockerコンテナを作成することなしにエンドポイント内で行うようにします。このために、SageMaker TensorFlow Serving Containerを利用します。

OpenAI Gym API for Fighting ICEを動かしてみる TL;DR Qiitaの方でコメントを頂いたので、早速gym-fightingiceを試してみました。

Keras BERTでファインチューニングしてみる TL;DR SentencePiece + 日本語WikipediaのBERTモデルをKeras BERTで利用するにおいて、Keras BERTを利用して日本語データセットの分類問題を扱って見ましたが、今回はファインチューニングを行ってみました。

SentencePiece + 日本語WikipediaのBERTモデルをKeras BERTで利用する TL;DR Googleが公開しているBERTの学習済みモデルは、日本語Wikipediaもデータセットに含まれていますが、Tokenizeの方法が分かち書きを前提としているため、そのまま利用しても日本語の分類問題ではあまり高い精度を得ることができません。

sumyを使って青空文庫を要約してみる TL;DR テキスト要約モジュールであるsumyを使って青空文庫の書籍を要約してみました。
sumyを使う部分はけ日記 - Python: LexRankで日本語の記事を要約するを参考にさせていただきました。 同記事ではTokenizerにJanomeを使用していますが、今回はginza(spacy)を使用しています。
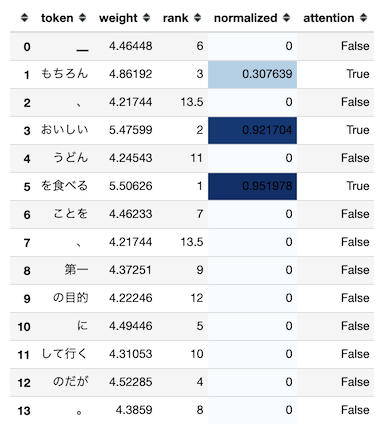
自然言語処理で使われるAttentionのWeightを可視化する TL;DR 自然言語処理で使われるAtentionのAttention Weight(Attention Weightを加味した入力シーケンス毎の出力)を可視化します。 これにより、モデルが推論を行った際に入力のどこに注目していたのかをユーザに表示することが可能です。

SentencePiece+word2vecでコーパスによる差を確認してみる TL;DR SentencePieceとword2vecを前提として、学習に利用したコーパスの違いでどの程度の差がでるか確認しました。 今回は以下のコーパスで比較しました。
Wikipediaja Wikipediaja+現代日本語書き言葉均衡コーパス それぞれのコーパスで学習したモデルを使用し、後述のベンチマーク用データを利用した分類問題の結果を評価しています。
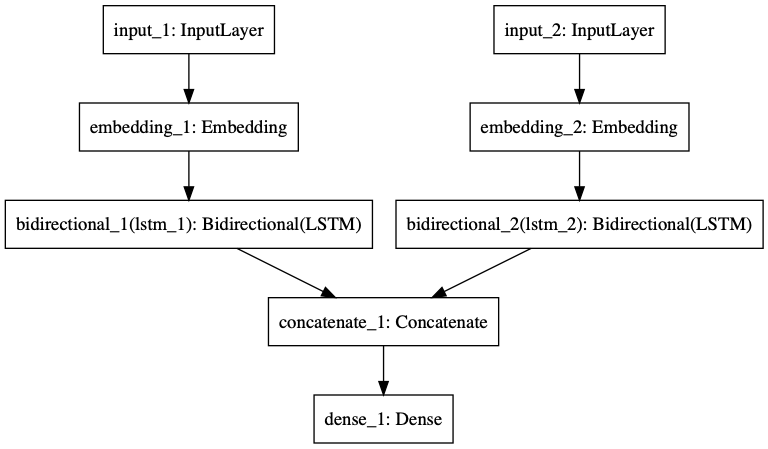
自然言語処理の分類問題の入力信号に、単語単位の入力だけではなく文字単位の入力を使用する TL;DR 自然言語処理の分類問題の入力信号では、単語単位での入力が一般的です。 但し、日本語のような表意文字圏では文字単位での入力にも意味があります。
LSTMを利用したネットワーク構造を利用して、単語単位であるか、文字単位であるか、それぞれ入力信号の違いでどのように結果に違いが出るかを比較してみました。
