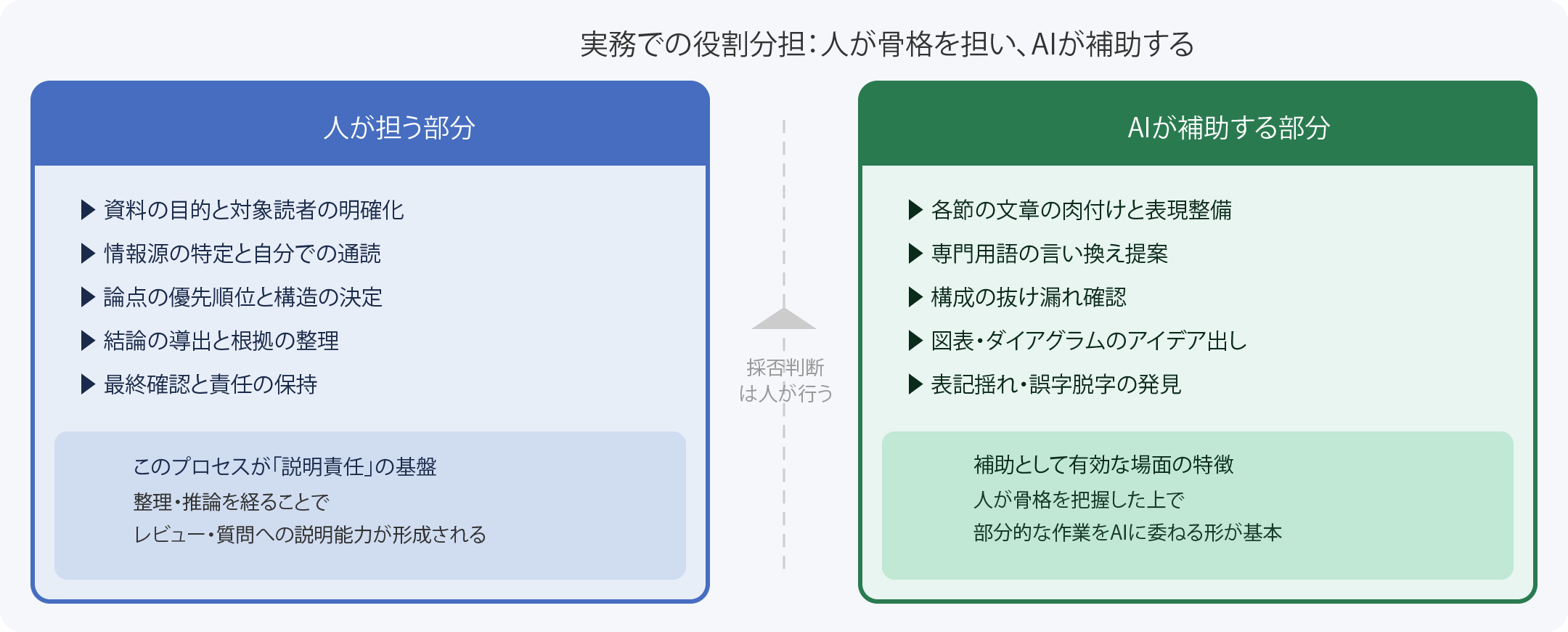
AIに資料を全面委任すると、なぜ手戻りが増えるのか 本稿では、生成AIを用いた資料作成における全面委任と補助活用の違いを、資料本来の目的・思考プロセス・手戻りコストの観点から整理しています。AIは資料の生成速度を大幅に向上させますが、情報整理・推論・説明責任という作業構造を踏まえると、全面委任の費用対効果は見かけ上の速さよりも低くなる場面が少なくありません。適切な役割分担によって品質と効率を両立させる方法についても合わせて紹介します。
はじめに 生成AIの普及により、資料の「初稿を出す速さ」は大幅に向上しました。プロンプトを入力すれば、数十秒でそれらしい文章や箇条書き、スライド構成が返ってきます。この速さは本物であり、補助的に活用する場面では確かに有効です。
しかし、速さだけに注目すると見落としがちな問題があります。「AIに任せたら早く完成した」にもかかわらず、レビューで大量の指摘が入る、関係者の質問に答えられない、修正の往復が何度も続く——このような状況は、AIを活用する現場で起きやすいパターンの一つです。
Claude Code の Agent Teamsで作成した「コード数行でAutoMLが動く——AutoGluon 1.5で試す4種類の機械学習タスク完全ガイド」 この記事は、以下の記事をもとにClaude CodeのAgent Teamsで作成したものです。
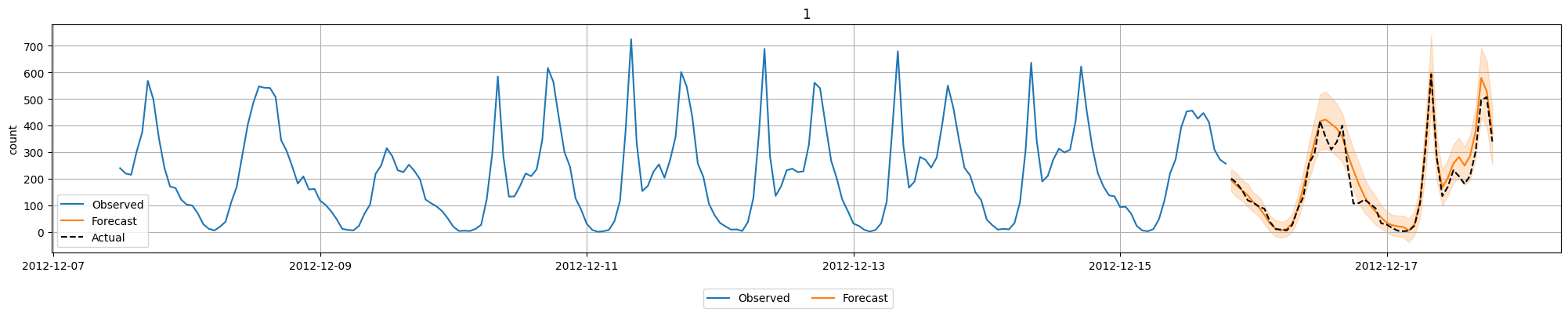
AutoGluonの基本的なAutoMLを試してみる AutoGluonは、Amazonが開発したオープンソースのAutoMLフレームワークです。今回、AutoGluonを利用して以下のタスクに関するAutoML機能を試してみました。
表形式データの分類 表形式データの回帰 時系列予測 画像分類 今回試した以外にも、AutoGluonは以下のように様々なタスクに対応しています。
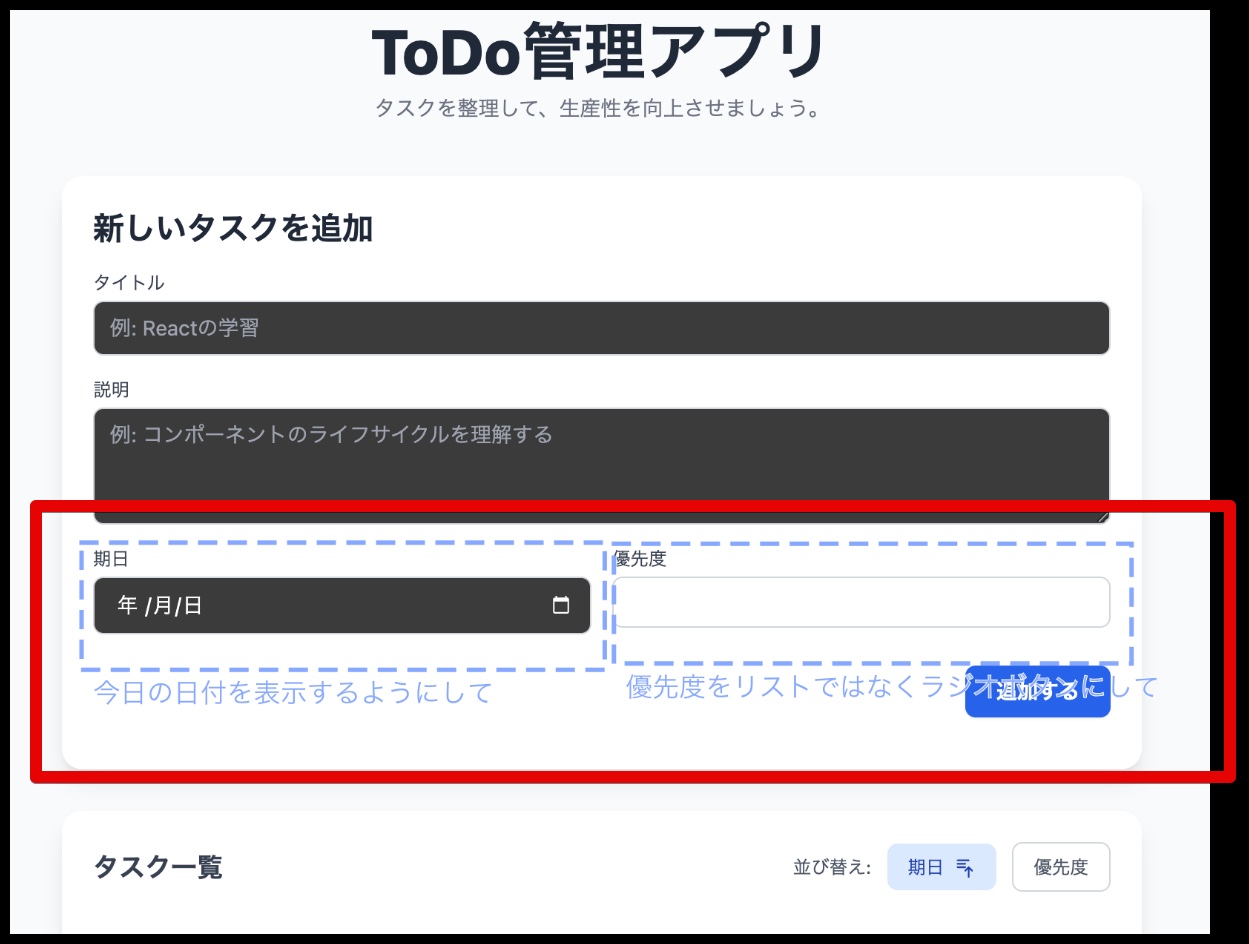
Google AI StudioでGUIへのアノテーションができるようになりました Google AI Studioは、AIを利用して対話的にWebアプリケーションを作成できる仕組みです。AIへ指示した結果がリアルタイムで反映され、プレビューで確認しながら開発を進められるため、効率的にアプリケーションを構築できます。
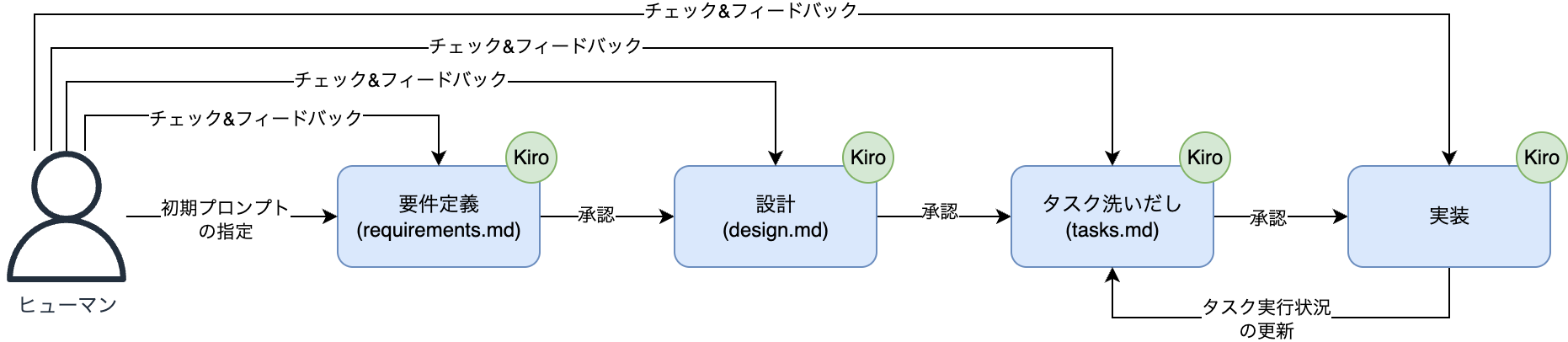
Kiro はシステム開発を変えるのか? AWS からKiroという新しいプログラミング用エディタが発表されました。Kiro は AI エージェントが統合された IDE であり、Cursor や Windsurf と同じ分野のエディタとなっています。しかしながら、Kiro は他の AI エディタとは異なり、以下の様にドキュメント駆動となっています。
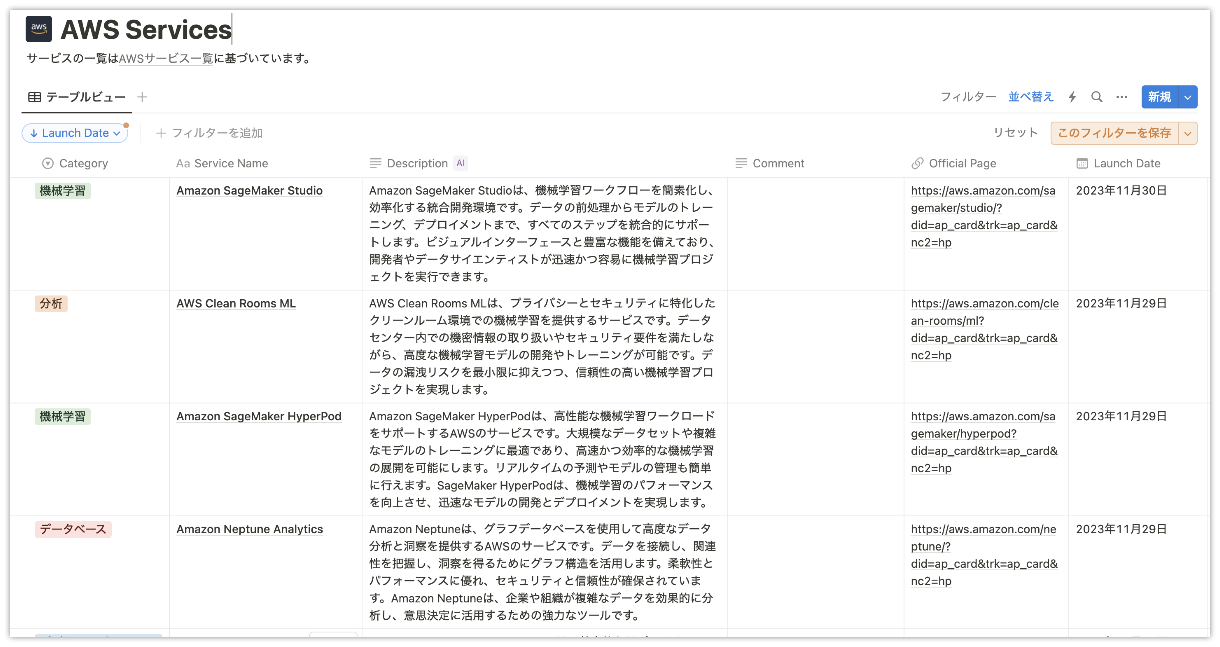
AWSサービス一覧をNotionデータベースでまとめる TL;DR AWS公式のAWS クラウド製品からサービス一覧を取得し、NotionデータベースにAPIとして登録してみました。各サービスの簡単な説明は、AWS クラウド製品でも記載されていますが、Notion AIを利用することでもう少し長めの説明を追記しています。
機械学習プロジェクトで必要な役割 前提とするフェーズ POCフェーズを想定しています。本格的な構築の際には、DevOps、SRAなど追加の役割が必要です。必要な知識の一覧についても同様です。 システム開発プロジェクトで必要なロールに限定しています。マーケターやビジネスアナリストなど、主に企画段階で要求されるロールは含めていません。 前提とするプロジェクトコミュニティ
機械学習プロジェクトの進め方 機械学習プロジェクトの流れ 機械学習を活用したシステム開発では、実験計画と工学的アプローチの両立が求められます。プロジェクトの目的と範囲を明確に定義することは不可欠ですが、実現方法は専門家の知見に基づいた実験的なアプローチに重点を置きます。そのため、試行錯誤のプロセスを迅速に繰り返し、必要な調整を行うことが重要です。
企画する https://www.mcgc.com/news_release/pdf/190718.pdf
最新のLLMを利用したシステム開発 LLMOpsのワークフロー LLMを利用したシステム開発では、LLM自体から開発する(基盤モデルの構築)、学習済みのLLMに対し、独自に収集したラベルデータで特定タスク向けに調整する(特定タスクへのファインチューニング)、学習済みのLLMをそのまま利用するが、RAGなどの仕組みで知識を補完する(独自データからの知識統合)という選択肢があります。
https://note.com/wandb_jp/n/n1aa6d77f33cf
LLMの発展によるAI/ML開発の変化 従来のLLMによるシステム開発 従来のLLM(Large Language Model, 大規模言語モデル)では、大量のコーパスにより事前学習モデル(これが言語モデル)を作成し、特定のタスクに特化した少量のラベルデータによりファインチューニングを行うことを想定していました。