
自然言語処理での応用 自然言語処理の概要 NLP(Natural Language Processing)とも言います。自然言語処理は、人の話す言葉をコンピュータに学習・理解させ、人の役に立つようにコンピュータに処理させることです。以下の様に様々な要素技術とその組み合わせにより構成されます。
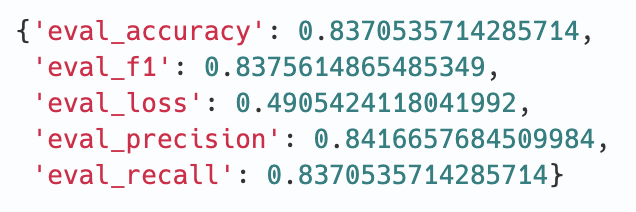
Huggingface TransformersでBERTをFine Tuningしてみる TL;DR 様々な自然言語処理モデルをお手軽に使えるHuggingface Transformersを利用し、日本語の事前学習済みBERTモデルのFine Tuningを試してみました。
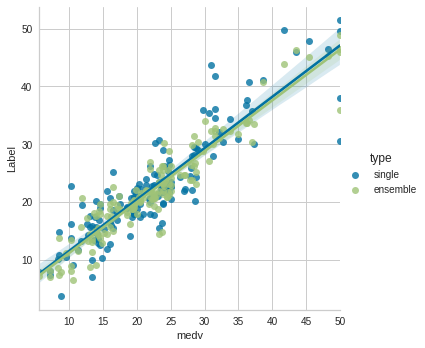
PyCaretで学ぶデータ分析におけるAutoMLの利用 TL;DR ボストン住宅価格データセットを利用して、データ分析におけるAutoMLの利用を解説します。 似たようなコンテンツは他にも色々有りますが、手動でのデータ分析からAutoMLの利用までの一連の流れを説明する機会があったので、その内容を纏めています。 以下のような流れでの解説です。

SageMakerで独自コンテナでトレーニングする方法 TL;DR AWS SageMakerで独自コンテナでトレーニングする方法です。 メトリクスの設定などを含めて必要最小限の設定でトレーニングするためのサンプルとなります。 ローカルモードとSageMaker上のトレーニングジョブとしての実行もフラグの切替で可能となっています。
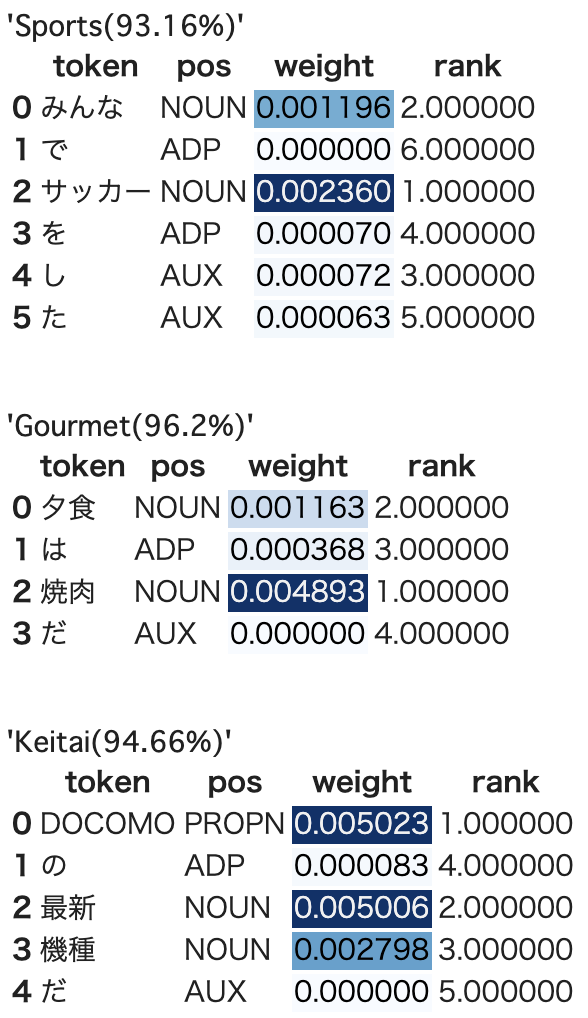
自然言語処理で使われるAttentionのWeightを可視化する(spaCy版) TL;DR 自然言語処理で使われるAtentionのAttention Weight(Attention Weightを加味した入力シーケンス毎の出力)を可視化します。 基本的に自然言語処理で使われるAttentionのWeightを可視化すると同様ですが、spaCyを利用したバージョンです。
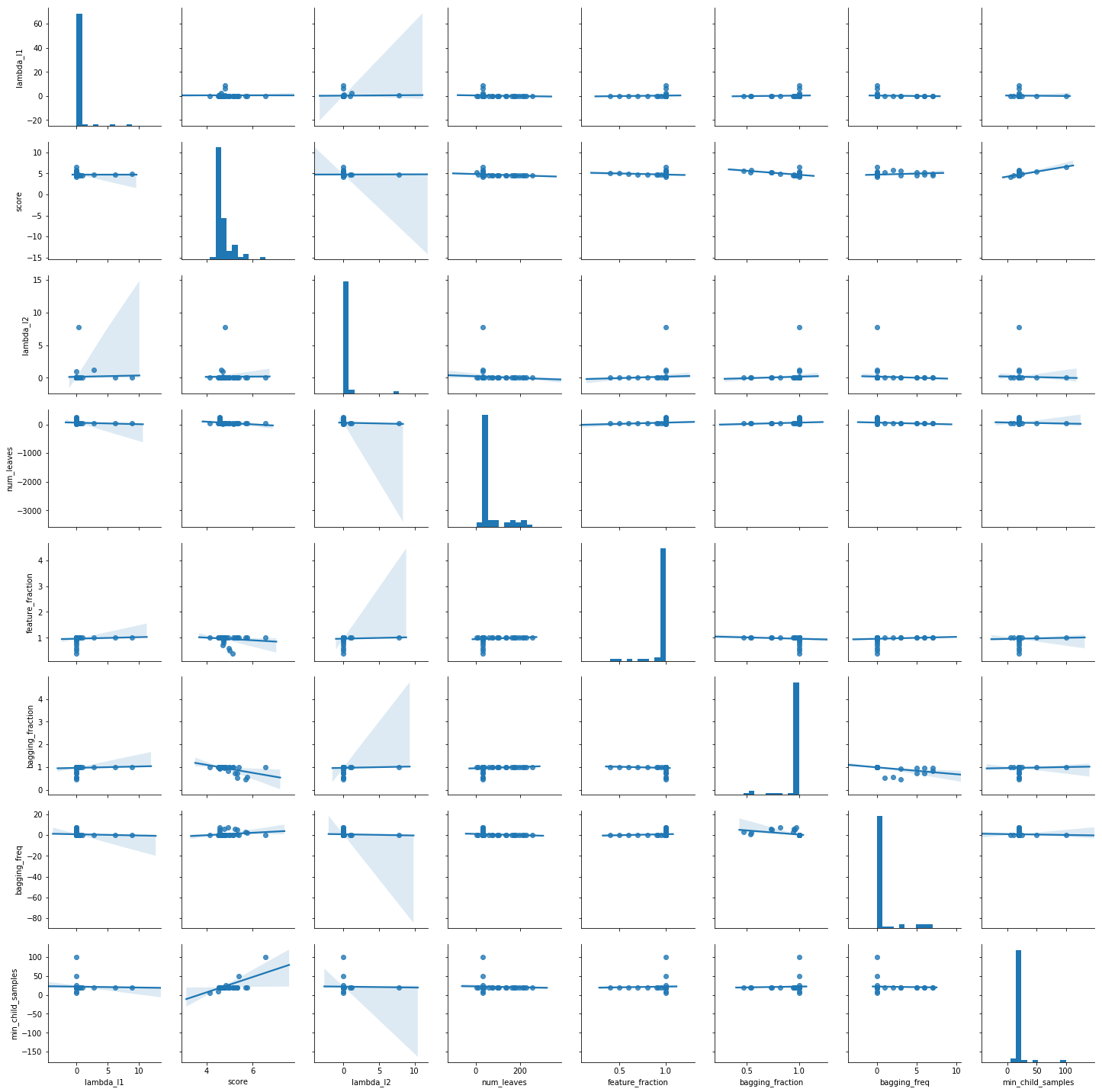
LightGBMをOptunaでパラメータチューニングする TL;DR LightGBMのパラメータをOptunaのLightGBM Tunerでチューニングします。 OptunaのLightGBM TunerはOptunaに組み込まれているLightGBM用のパラメータチューナーです。
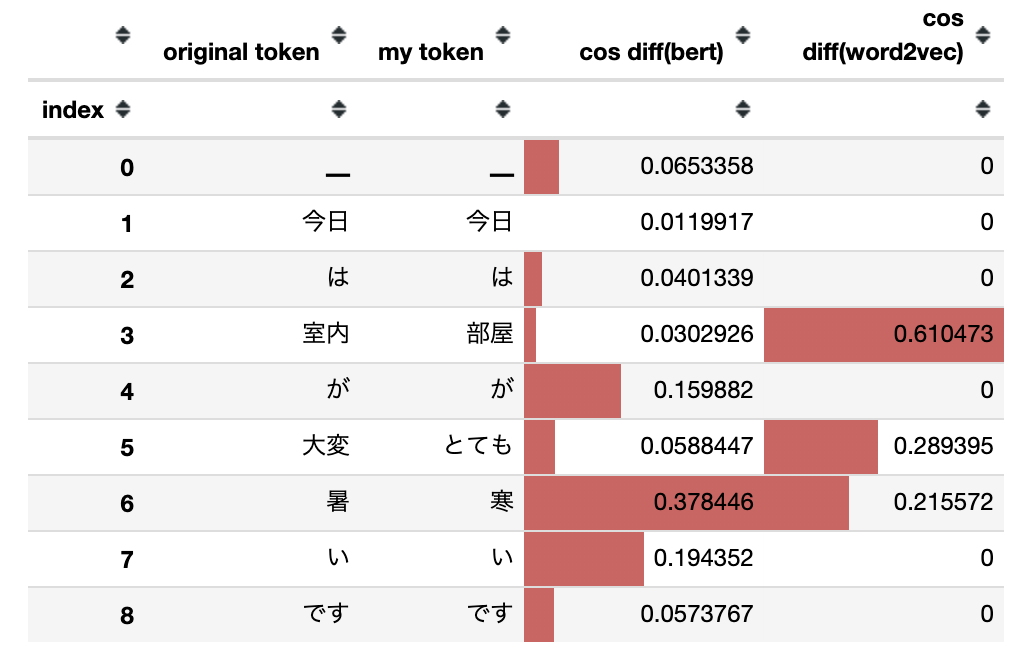
BERTおよびWord2Vecで文の類似性を確認する TL;DR 文の類似性を確認する方法としてBERTとWord2Vecを比較します。 文全体の類似性ではなくトークン単位での比較です。
BERTとWord2Vecによるベクトル化にはtext-vectorianを使用します。
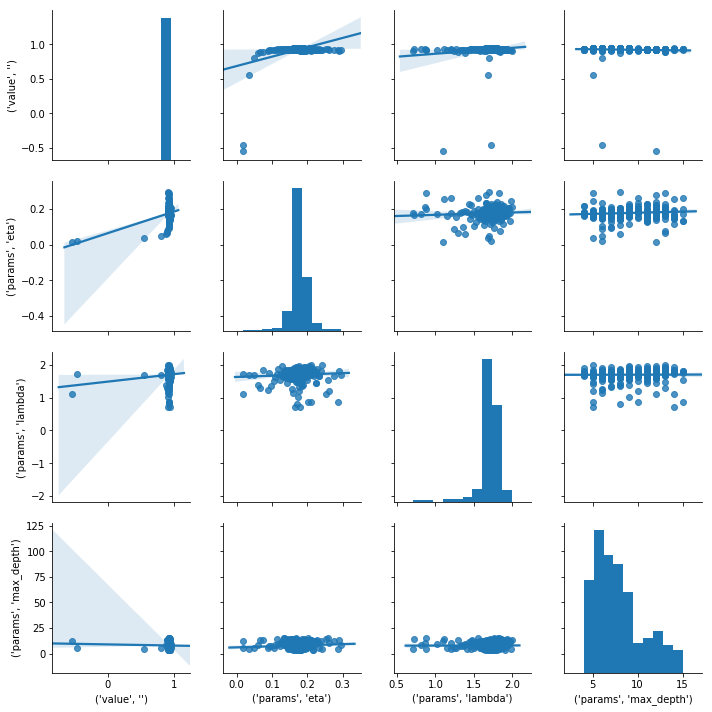
XGBoostをOptunaでパラメータチューニングする TL;DR XGBoostのパラメータをOptunaでチューニングします。 ベンチマーク用データとしてはボストン住宅価格データセットを使用します。
データ準備 scikit-learnのdatasetsを使ってデータをロードします。 学習データとテストデータの分割は8:2です。
もっと簡単に Keras BERT でファインチューニングしてみる TL;DR text-vectorianをバージョンアップし、BERT のファインチューニングで役に立つ機能を追加しました。

SageMakerでKerasの独自モデルをトレーニングしてデプロイするまで(Python3対応) TL;DR AWS SageMakerにおいて、Kerasによる独自モデルをトレーニングし、SageMakerのエンドポイントとしてデプロイします。 また、形態素解析やベクトル化のような前処理を、個別にDockerコンテナを作成することなしにエンドポイント内で行うようにします。このために、SageMaker TensorFlow Serving Containerを利用します。
