PandasのDataFrameに対して、Amazon Bedrockを利用した処理を並列で呼び出す方法 PandasのDataFrameに対して、Amazon Bedrockを利用した処理を並列で呼び出す方法を調べてみました。PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法のAmazon Bedrockバージョンです。こちらも端的にはpandarallelを使いましょう、です。
PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法 PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法を調べてみました。結論としては、pandarallelを使うのが最も簡単だろうという感じです。
from pandarallel import pandarallel pandarallel.initialize() summary_df["summary"] = summary_df["url"].parallel_apply(get_summary) display(summary_df) 前提条件 openai==1.16.2 pandarallel==1.6.5 事前準備 from __future__ import annotations import openai import urllib import pandas as pd urls = [ "https://www.inoue-kobo.com/llm/openai-reduce-embedding-dim/", "https://www.inoue-kobo.com/aws/selenium-serverless/", "https://www.inoue-kobo.com/aws/aws-service-summary/", "https://www.inoue-kobo.com/ai_ml/duckduckgo-langchain-langsmith/", "https://www.inoue-kobo.com/ai_ml/llamaindex-pdf-gradio/", ] summary_df = pd.DataFrame(urls, columns=["url"]) pd.set_option("display.max_colwidth", None) 単純に apply するだけ def get_summary(url: str) -> str | None: res_web = urllib.request.urlopen(url) # type: ignore content = res_web.read().decode("utf-8") res_openai = openai.chat.completions.create( model="gpt-3.5-turbo", temperature=0, messages=[ { "role": "system", "content": "以下はWebサイトの内容です。HTMLタグを削除した上で、150文字以内で要約してください。", }, {"role": "user", "content": content}, ], ) return res_openai.choices[0].message.content summary_df["summary"] = summary_df["url"].apply(get_summary) display(summary_df) 実行時間は12.3sでした。applyしただけでは並列処理は行われないため、この処理時間が基準になります。
OpenAI API Embeddings の dim 指定の実装方法を確認した OpenAI API として新しくリリースされたベクトル表現取得用モデルである text-embedding-3 では、出力の次元数を指定できるようになりました。どうやってるのかな?と気になったので、実装方法を確認してみました。結論から言うと、以下の公式ドキュメントに書いてある実装方法のショートカットでした(その旨がドキュメントに書いてあります)。
LangChain Evaluation の String Evaluators のまとめ LangChain Evaluation の String Evaluators について、提供されている EvaluatorType の挙動を一通り確認してみました。
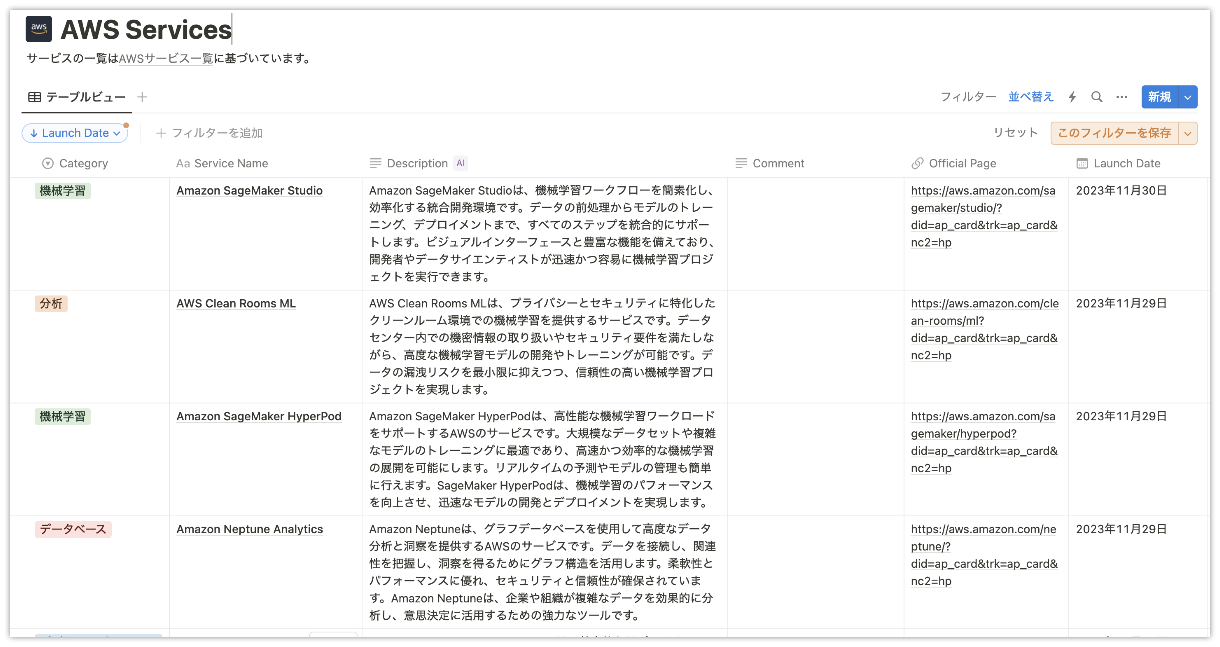
AWSサービス一覧をNotionデータベースでまとめる TL;DR AWS公式のAWS クラウド製品からサービス一覧を取得し、NotionデータベースにAPIとして登録してみました。各サービスの簡単な説明は、AWS クラウド製品でも記載されていますが、Notion AIを利用することでもう少し長めの説明を追記しています。
機械学習プロジェクトで必要な役割 前提とするフェーズ POCフェーズを想定しています。本格的な構築の際には、DevOps、SRAなど追加の役割が必要です。必要な知識の一覧についても同様です。 システム開発プロジェクトで必要なロールに限定しています。マーケターやビジネスアナリストなど、主に企画段階で要求されるロールは含めていません。 前提とするプロジェクトコミュニティ
SeleniumをAWS Lambdaでサーバーレスに動かしてみる TL;DR APIが提供されていないなどの理由で、Seleniumを使ってWebサービスを操作する際に、サーバーレスで実行できると便利ですが、AWS Lambdaで実行するためには依存モジュールなどの調整が必要です。このあたりの面倒な作業については、有難いことに以下のリポジトリで開発されています。
機械学習プロジェクトの進め方 機械学習プロジェクトの流れ 機械学習を活用したシステム開発では、実験計画と工学的アプローチの両立が求められます。プロジェクトの目的と範囲を明確に定義することは不可欠ですが、実現方法は専門家の知見に基づいた実験的なアプローチに重点を置きます。そのため、試行錯誤のプロセスを迅速に繰り返し、必要な調整を行うことが重要です。
企画する https://www.mcgc.com/news_release/pdf/190718.pdf
最新のLLMを利用したシステム開発 LLMOpsのワークフロー LLMを利用したシステム開発では、LLM自体から開発する(基盤モデルの構築)、学習済みのLLMに対し、独自に収集したラベルデータで特定タスク向けに調整する(特定タスクへのファインチューニング)、学習済みのLLMをそのまま利用するが、RAGなどの仕組みで知識を補完する(独自データからの知識統合)という選択肢があります。
https://note.com/wandb_jp/n/n1aa6d77f33cf
LLMの発展によるAI/ML開発の変化 従来のLLMによるシステム開発 従来のLLM(Large Language Model, 大規模言語モデル)では、大量のコーパスにより事前学習モデル(これが言語モデル)を作成し、特定のタスクに特化した少量のラベルデータによりファインチューニングを行うことを想定していました。