
機械学習プロジェクトの進め方
機械学習プロジェクトの進め方
機械学習プロジェクトの流れ
機械学習を活用したシステム開発では、実験計画と工学的アプローチの両立が求められます。プロジェクトの目的と範囲を明確に定義することは不可欠ですが、実現方法は専門家の知見に基づいた実験的なアプローチに重点を置きます。そのため、試行錯誤のプロセスを迅速に繰り返し、必要な調整を行うことが重要です。
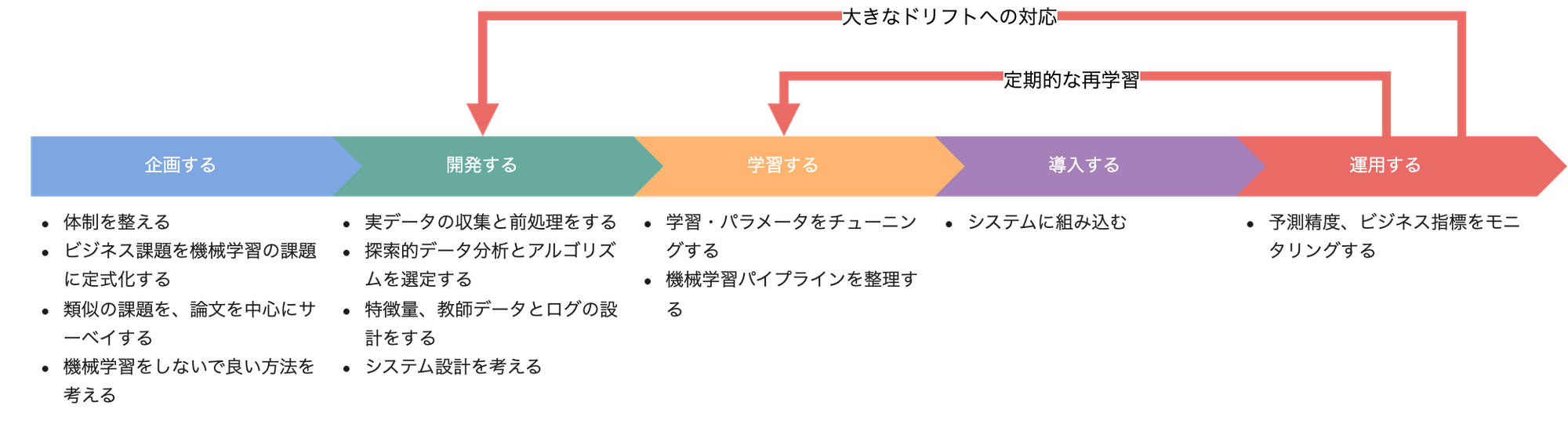
企画する
- 体制を整える
- ビジネス課題を機械学習の課題に定式化する
- 類似の課題を、論文を中心にサーベイする
- 機械学習をしないで良い方法を考える
体制を整える
企画段階では、ビジネス課題を理解し、専門知識に基づいて解決策を検討する必要があります。機械学習が解決手段として想定される場合、以下の役割を担当できるメンバーをアサインし、企画を検討できる体制を整えることになります。
- ドメインエキスパート(業務の専門家)
- データサイエンティスト
- システムアーキテクト
- 機械学習エンジニア
- プロダクトオーナーの候補となる責任者
ビジネス課題を機械学習の課題に定式化する
まずはビジネス課題を十分に理解する必要があります。ビジネスおよび対象となる課題の理解にはドメインエキスパートの協力が必須です。
課題の理解を進めるためには、データの分析も必要です。業務上のデータを分析することで、課題への理解や解決策の検討に必要なインサイトを得ることができます(EDA、探索的データ分析)。データの分析はデータサイエンティストの役割です。必要なデータが不足している場合は、データの収集から行う必要があります。この際、既存の業務システムからのデータ取得や整理、分析できる状態への変換などにはシステムアーキテクトや機械学習エンジニアの役割が必要になることがあります。
ビジネスおよびビジネス課題への理解、EDAで得られたインサイトを元に、機械学習でどのように課題を解決できるのかを検討します。
類似の課題を、論文を中心にサーベイする
機械学習を用いた課題解決には、多くの時間とコストが必要です。しかし、機械学習による課題解決方法は論文や事例として既に存在していることが多く、類似の解決策を調査することで検討時間を短縮できる可能性があります。そのため、まずは類似課題の調査から始めることが推奨されます。
調査には専門的な知識が必要ですので、データサイエンティストまたはリサーチャーと呼ばれる専門の役割の担当者が実施することがあります。
機械学習をしないで良い方法を考える
機械学習による課題解決は高コストな方法です。構築するシステムは複雑であり、運用中に発生する問題も解決に専門的な知識を要するものが多いため、大きな技術的負債になります。そのため、機械学習以外の方法でビジネス課題を解決することがベストです。本当に機械学習を用いる必要があるのか、プロジェクトメンバー全員で十分に確認します。
開発する
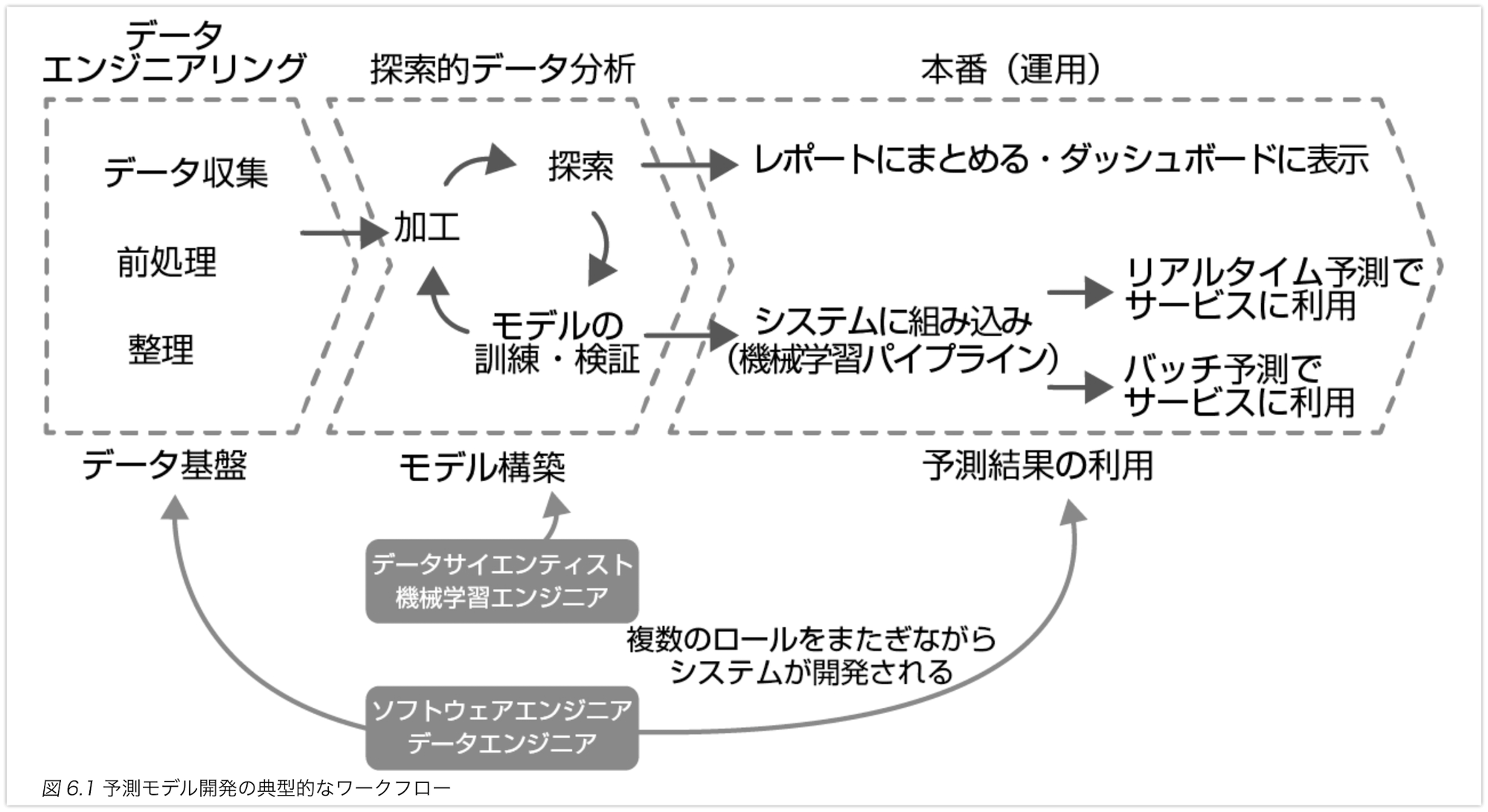
仕事ではじめる機械学習 第2版 より引用。
- 実データの収集と前処理をする
- 探索的データ分析とアルゴリズムを選定する
- 特徴量、教師データとログの設計をする
- システム設計を考える
実データの収集と前処理をする
実データを収集する際には、多くの情報を収集することが重要です。また、収集したデータを機械学習モデルの学習に使用するためには、前処理を行う必要があります。前処理には、欠損値の処理やスケーリングなどの基本的な手法が含まれます。また、カテゴリカルデータのエンコーディングを行うことも重要です。これらの前処理手法を適用することで、より正確な予測モデルを構築することができます。
探索的データ分析とアルゴリズムを選定する
収集した実データに対して探索的データ分析を行います。探索的データ分析は、データの特徴やパターンを詳しく調査することにより、データの品質や分布、外れ値の有無などを把握することができます。これにより、データの解釈や分析方法の選択に役立ちます。また、アルゴリズムや特徴量の選択にも重要な情報を提供します。探索的データ分析は、データの理解を深めるために欠かせないプロセスです。
特徴量、教師データとログの設計をする
特徴量の設計は機械学習の性能に大きな影響を与えます。特徴量は、機械学習モデルに入力されるデータの属性や変数を表します。特徴量の選択や抽出方法、スケーリングなどを検討し、モデルの学習に適した形式でデータを準備する必要があります。
教師データは、機械学習モデルの訓練に使用する正解データです。正解データは、特徴量と対応する目標変数(またはラベル)のペアで構成されます。教師データは人が手動で設定する場合があります(アノテーション)。
ログは、モデルの学習や予測の過程で生成される情報の記録です。ログは、モデルの性能評価やデバッグ、再現性の確保などに役立ちます。どのような情報を記録するか、どのような形式で保存するかを検討し、ログの設計を行います。
システム設計を考える
MLOps、LLMOps、課題に応じた推論方法に基づいたシステム構成を検討します。具体的な内容は以下を参照してください。
学習する
- 学習・パラメータをチューニングする
- 機械学習パイプラインを整理する
学習・パラメータをチューニングする
実データを前処理して変換した特徴量と教師データを使用してモデルを学習します。データは学習用と評価用に分割し、事前に検討した評価指標に基づいてモデルの性能を評価します。
モデルの学習時には、選定したアルゴリズムに応じてさまざまなハイパーパラメータが存在します。これらのハイパーパラメータについても、評価指標を目標として最適化を行います。ハイパーパラメータの最適化の程度は、利用可能な計算リソースや時間などに応じて判断します。
機械学習パイプラインを整理する
学習したモデルを本番環境に導入するために、機械学習パイプラインを整理します。これには、データの前処理や特徴量エンジニアリングの自動化、モデルの更新や再学習のスケジューリングなどが含まれます。適切なパイプラインを構築することで、モデルの導入や運用を効率化し、品質を維持することができます。
導入する
- システムに組み込む
システムに組み込む
機械学習パイプラインを構築し、モデルを利用するシステムに導入します。
運用する
- 予測精度、ビジネス指標をモニタリングする
予測精度、ビジネス指標をモニタリングする
モデルが本番環境で運用されている間、さまざまな指標をモニタリングします。実データの変化やモデル学習時の評価指標だけでなく、機械学習モデルを利用したシステムがビジネスに与える影響を評価するために、ビジネス指標の定義とモニタリングも重要です。モデルの精度改善は手段であり、本当に改善すべきビジネス指標への影響を観測できなければ意味がありません。
予測精度の変化やビジネス指標の変動を把握し、モデルのパフォーマンスやビジネスへの影響を評価し、継続的な改善を行います。