
SentencePiece+word2vecでコーパスによる差を確認してみる TL;DR SentencePieceとword2vecを前提として、学習に利用したコーパスの違いでどの程度の差がでるか確認しました。 今回は以下のコーパスで比較しました。
Wikipediaja Wikipediaja+現代日本語書き言葉均衡コーパス それぞれのコーパスで学習したモデルを使用し、後述のベンチマーク用データを利用した分類問題の結果を評価しています。
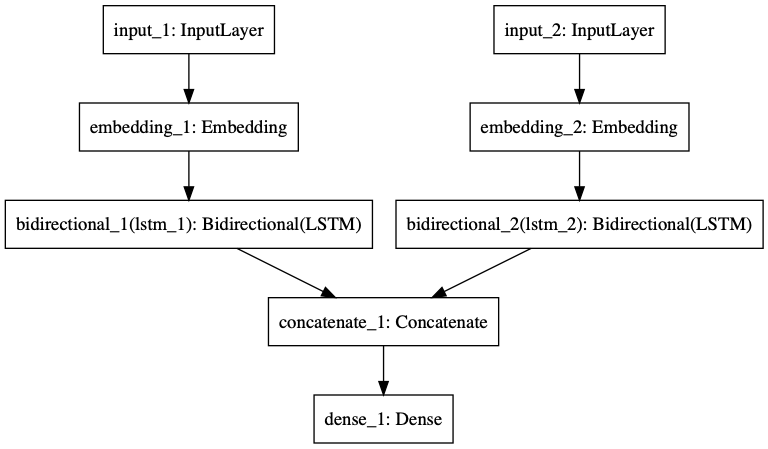
自然言語処理の分類問題の入力信号に、単語単位の入力だけではなく文字単位の入力を使用する TL;DR 自然言語処理の分類問題の入力信号では、単語単位での入力が一般的です。 但し、日本語のような表意文字圏では文字単位での入力にも意味があります。
LSTMを利用したネットワーク構造を利用して、単語単位であるか、文字単位であるか、それぞれ入力信号の違いでどのように結果に違いが出るかを比較してみました。
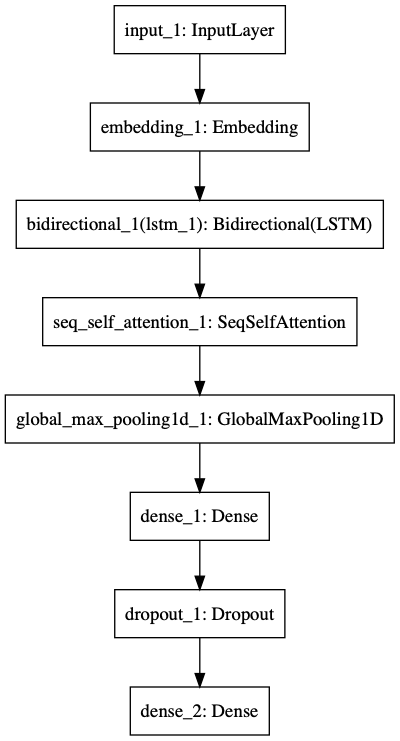
Self-Attentionを利用したテキスト分類 TL;DR テキスト分類問題を対象に、LSTMのみの場合とSelf-Attentionを利用する場合で精度にどのような差がでるのかを比較しました。 結果、テキスト分類問題においても、Self-Attentionを利用することで、LSTMのみを利用するよりも高い精度を得られることが確認できました。
Self-Attentionの実装としてはkeras-self-attentionを利用しました。
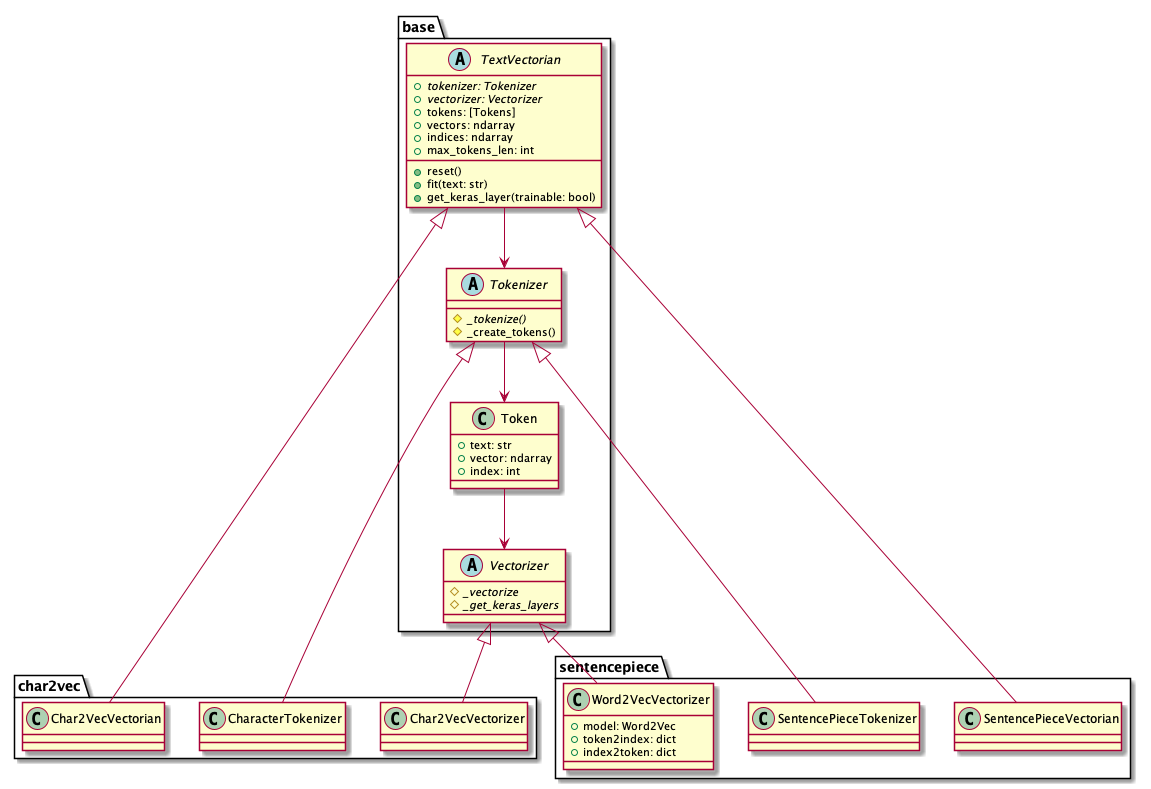
自然言語ベクトル化用Pythonモジュール(text-vectorian)をリリースしました TL;DR text-vectgorianは、自然言語をベクトル化するためのPythonモジュールです。 TokenizerやVectorizerの詳細を気にすることなく、任意のテキストから簡単にベクトル表現を取得することが可能です。 日本語Wikipediaで学習済みのモデルを同梱しているため、モジュールをインストールしてすぐに利用することができます。

Auto-KerasでTextClassifierを使って見る TL;DR Auto-KerasでTextClassifierを使って見ました。 Auto-Kerasを利用した画像分類(ImageClassifier)については、Auto-Kerasを使って見るを参照してください。
Auto-Kerasのバージョンは0.3.5です。
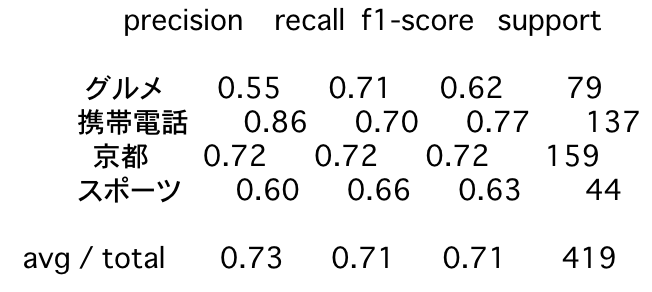
各種Tokenize手法に依存したベクトル化手法の比較 TL;DR 以下のベクトル化手法を比較しました。
wikipedia2vec sentencepieces + word2vec char2vec ベクトル化するための学習データとして日本語Wikipediaを使用しました。
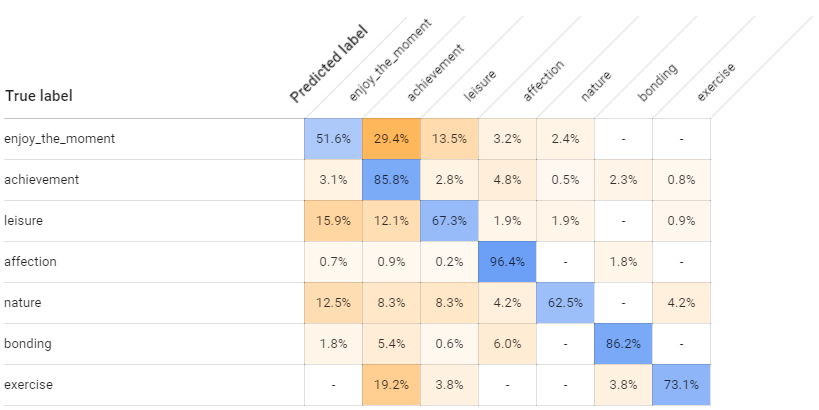
GCP AutoML Natural Languageのベンチマーク TL;DR デモデータを利用してAutoML Natural Languageと自作モデルの性能を比較してみました。 もう全部AutoML Natural Languageでいいんじゃないかなぁ・・・。
