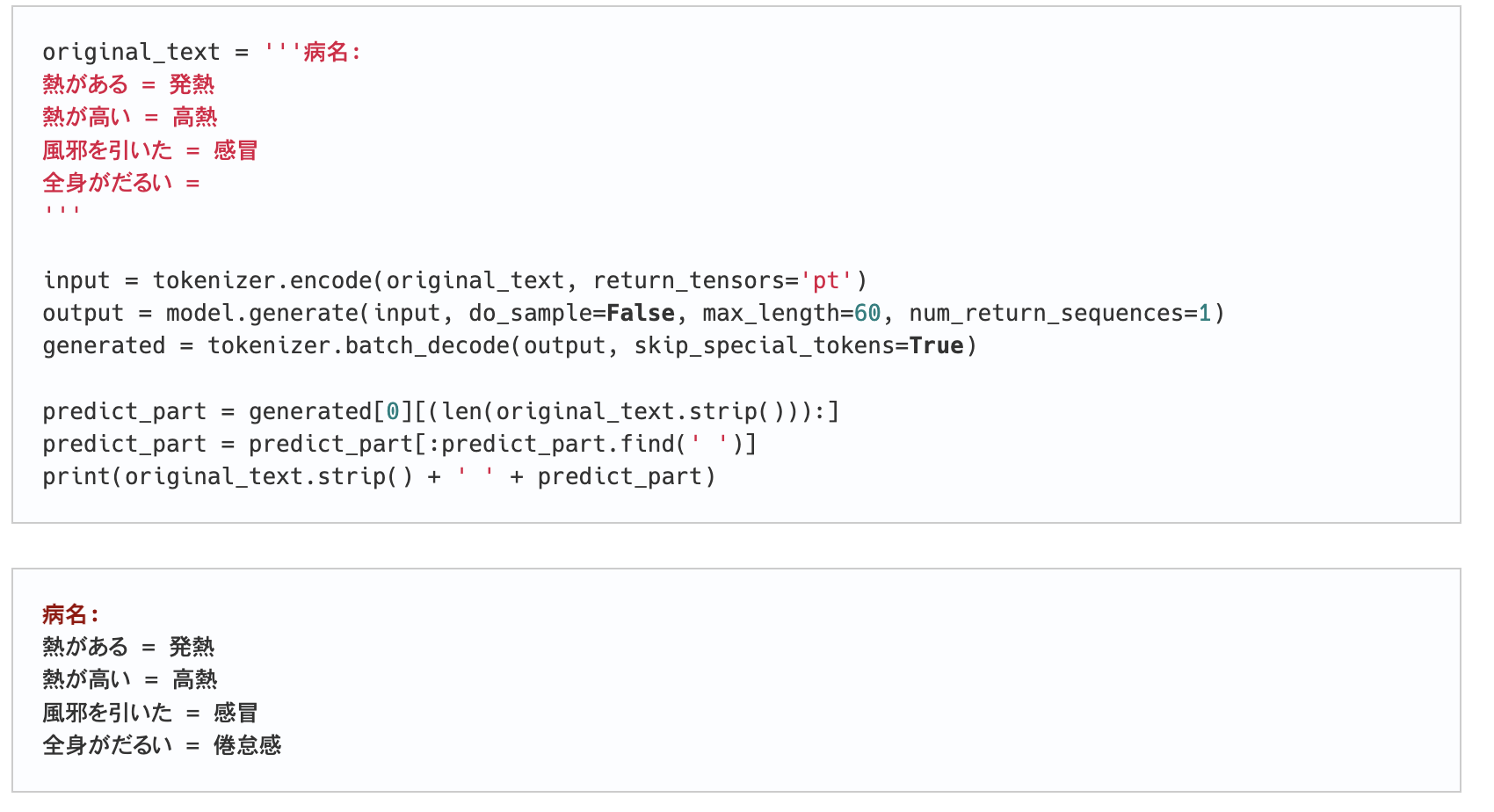
Huggingface Transformersによる日本語GPT-2モデルのrinnaを利用した推論の例 TL;DR Huggingface Transformersにより、日本語GPT-2モデルであるrinnaの公開モデルで以下の推論を行う場合のサンプルです。

自然言語処理での応用 自然言語処理の概要 NLP(Natural Language Processing)とも言います。自然言語処理は、人の話す言葉をコンピュータに学習・理解させ、人の役に立つようにコンピュータに処理させることです。以下の様に様々な要素技術とその組み合わせにより構成されます。
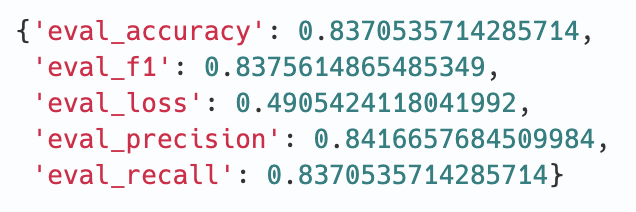
Huggingface TransformersでBERTをFine Tuningしてみる TL;DR 様々な自然言語処理モデルをお手軽に使えるHuggingface Transformersを利用し、日本語の事前学習済みBERTモデルのFine Tuningを試してみました。
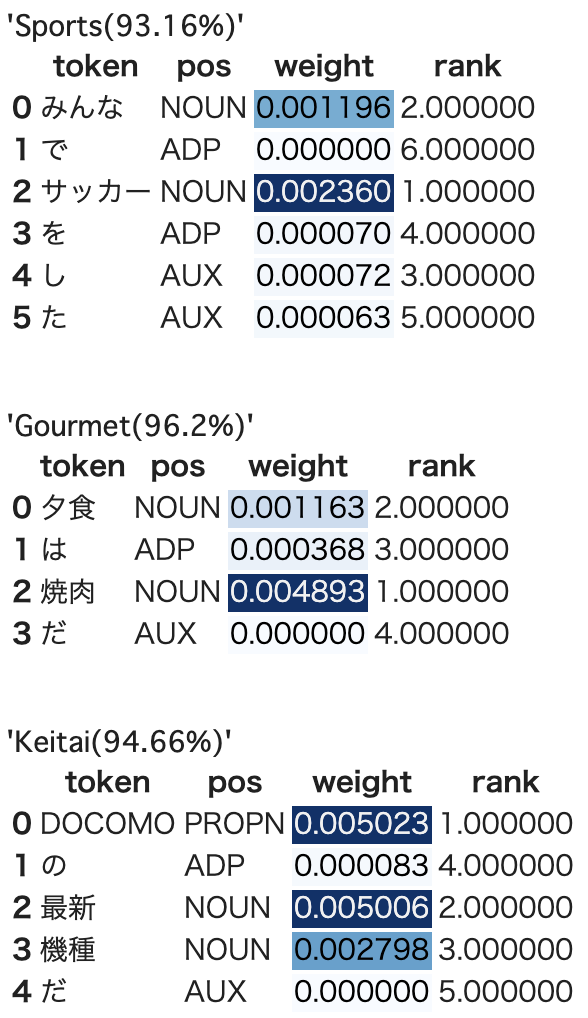
自然言語処理で使われるAttentionのWeightを可視化する(spaCy版) TL;DR 自然言語処理で使われるAtentionのAttention Weight(Attention Weightを加味した入力シーケンス毎の出力)を可視化します。 基本的に自然言語処理で使われるAttentionのWeightを可視化すると同様ですが、spaCyを利用したバージョンです。
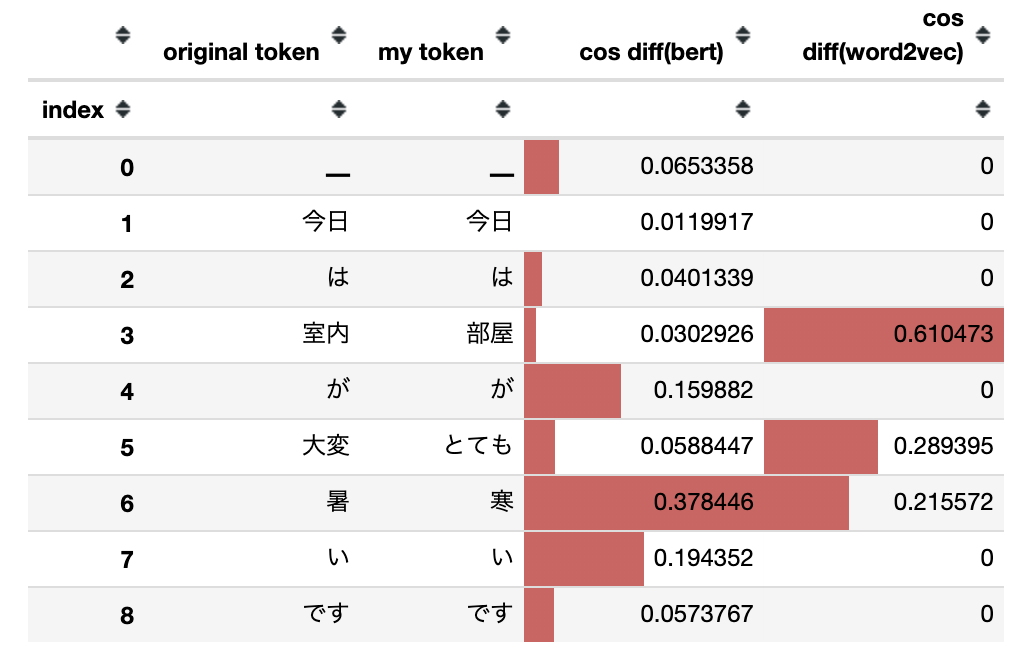
BERTおよびWord2Vecで文の類似性を確認する TL;DR 文の類似性を確認する方法としてBERTとWord2Vecを比較します。 文全体の類似性ではなくトークン単位での比較です。
BERTとWord2Vecによるベクトル化にはtext-vectorianを使用します。
もっと簡単に Keras BERT でファインチューニングしてみる TL;DR text-vectorianをバージョンアップし、BERT のファインチューニングで役に立つ機能を追加しました。

Keras BERTでファインチューニングしてみる TL;DR SentencePiece + 日本語WikipediaのBERTモデルをKeras BERTで利用するにおいて、Keras BERTを利用して日本語データセットの分類問題を扱って見ましたが、今回はファインチューニングを行ってみました。

SentencePiece + 日本語WikipediaのBERTモデルをKeras BERTで利用する TL;DR Googleが公開しているBERTの学習済みモデルは、日本語Wikipediaもデータセットに含まれていますが、Tokenizeの方法が分かち書きを前提としているため、そのまま利用しても日本語の分類問題ではあまり高い精度を得ることができません。

sumyを使って青空文庫を要約してみる TL;DR テキスト要約モジュールであるsumyを使って青空文庫の書籍を要約してみました。
sumyを使う部分はけ日記 - Python: LexRankで日本語の記事を要約するを参考にさせていただきました。 同記事ではTokenizerにJanomeを使用していますが、今回はginza(spacy)を使用しています。
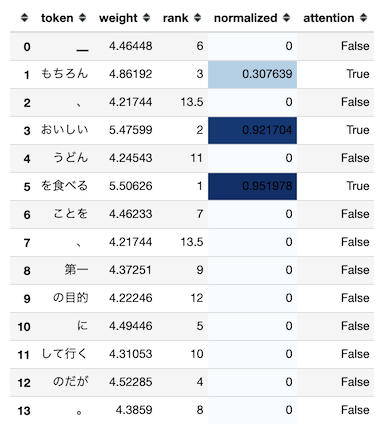
自然言語処理で使われるAttentionのWeightを可視化する TL;DR 自然言語処理で使われるAtentionのAttention Weight(Attention Weightを加味した入力シーケンス毎の出力)を可視化します。 これにより、モデルが推論を行った際に入力のどこに注目していたのかをユーザに表示することが可能です。
