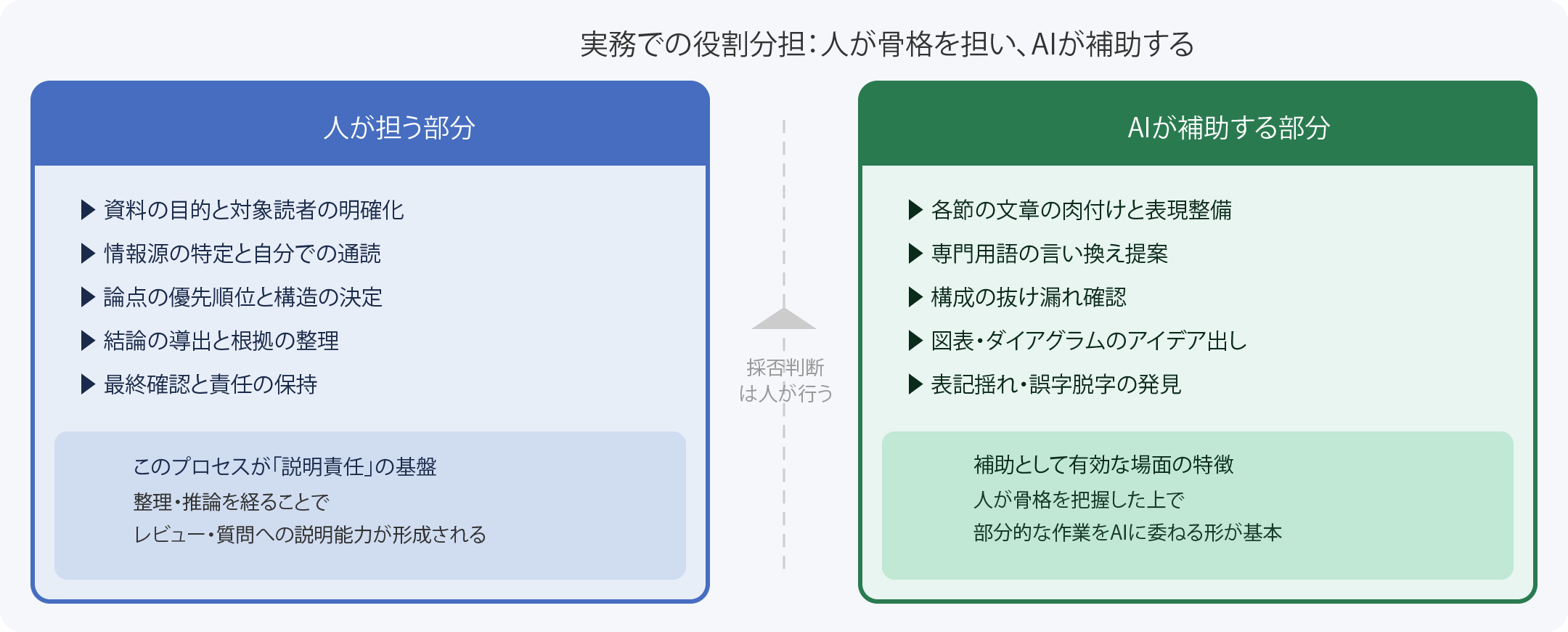
AIに資料を全面委任すると、なぜ手戻りが増えるのか 本稿では、生成AIを用いた資料作成における全面委任と補助活用の違いを、資料本来の目的・思考プロセス・手戻りコストの観点から整理しています。AIは資料の生成速度を大幅に向上させますが、情報整理・推論・説明責任という作業構造を踏まえると、全面委任の費用対効果は見かけ上の速さよりも低くなる場面が少なくありません。適切な役割分担によって品質と効率を両立させる方法についても合わせて紹介します。
はじめに 生成AIの普及により、資料の「初稿を出す速さ」は大幅に向上しました。プロンプトを入力すれば、数十秒でそれらしい文章や箇条書き、スライド構成が返ってきます。この速さは本物であり、補助的に活用する場面では確かに有効です。
しかし、速さだけに注目すると見落としがちな問題があります。「AIに任せたら早く完成した」にもかかわらず、レビューで大量の指摘が入る、関係者の質問に答えられない、修正の往復が何度も続く——このような状況は、AIを活用する現場で起きやすいパターンの一つです。
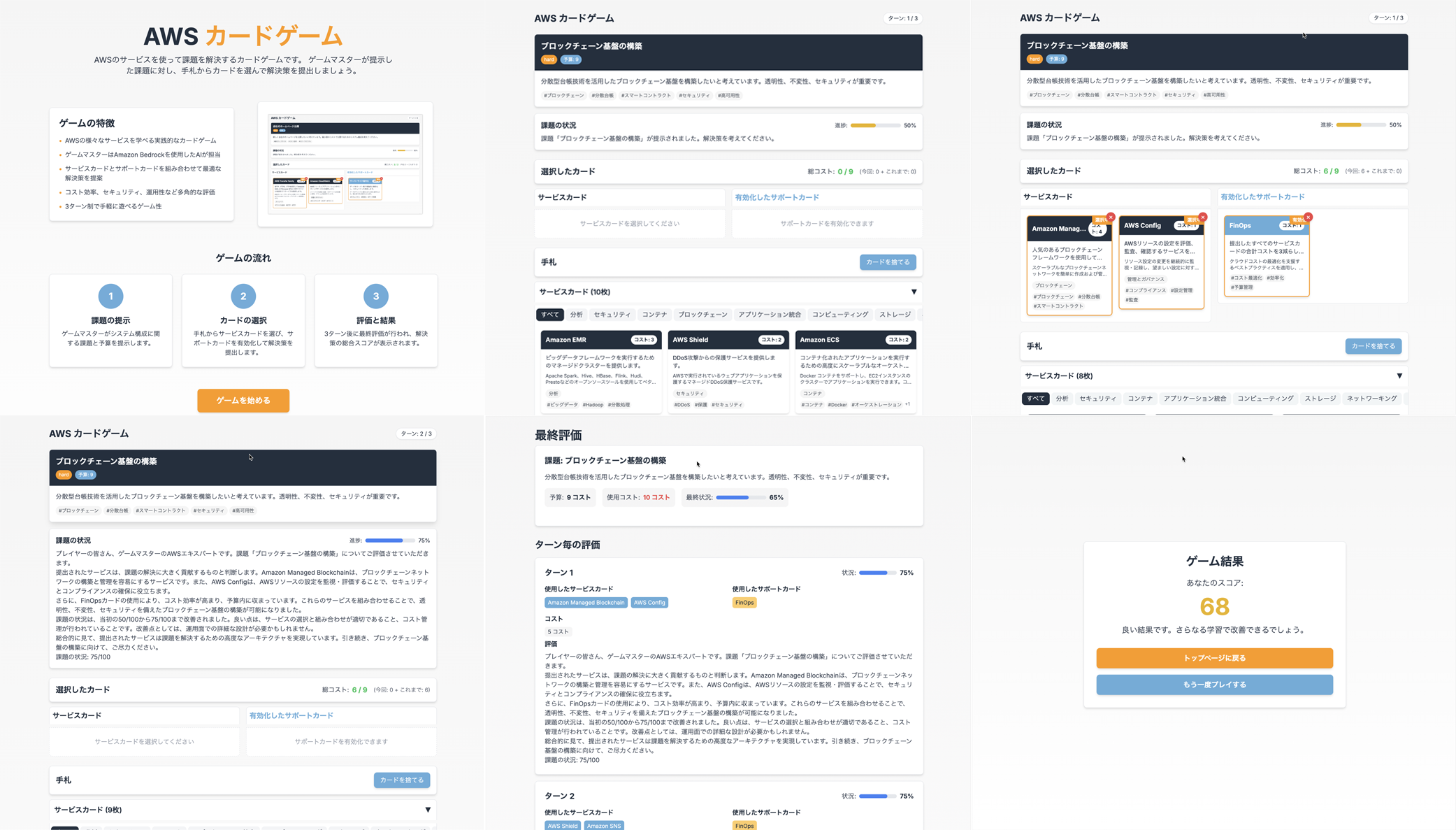
Amazon Q CLIでゲームを作ってAppRunnerでホスティングする Amazon Q CLIを使って簡単なカードゲームを作成し、AppRunnerでホスティングする方法です。本記事は以下のキャンペーン目的ですが、ゲームを作るというのはAIエージェントでできることを体験するのに良い方法だと思います。
AWS Strands Agentsを使ってAWSのシステム構成図を作成する AWS Strands Agentsを使ってAWSのシステム構成図を作成する方法のご紹介です。AWSからはCloudFormationの情報を操作するためのMCP Serverが提供されています。これを利用して、AWSのシステム構成図を作成する方法を確認してみました。
AWS Strands Agentsをクロスリージョン推論で利用する 先日、AWSからOSSとしてStrands Agentsがリリースされました。Strands Agentsは、AIエージェントを簡単に作成できるフレームワークです。以下のブログでMCP Serverを利用するためのデモが紹介されています。今回、Strands AgentsをAmazon Bedrockのクロスリージョン推論を利用して、東京リージョンで利用する方法を確認してみました。
メタドキュメント作成のススメ システム開発では、設計書、ソースコード、サーバー構築手順書、業務手順書など、多様な成果物を複数の関係者やツールと協調しながら作成します。本稿では、生成AIと人間が共通の品質基準で成果物を作成できるよう、その指針となる メタドキュメント の作成と運用ワークフローについて説明しています。
メタドキュメントとは何か メタドキュメントは成果物そのものを直接記述するのではなく、成果物を生成・レビュー・保守するためのルール、構造、品質基準をメタレベルで定めた文書群です。以下のような文書が該当します。
LLMの最新トレンド - 2025年3月 そもそもLLMとは? LLMは Large Language Model の略であり、日本語では大規模言語モデルと表記します。要は言語モデルの大きいものという意味ですが、そもそも言語モデルとは何でしょうか。LLMのトレンドをご紹介する前に、LLMそのものの理解を深めた方がわかりやすいため、簡単にLLMの中身について説明します。
PandasのDataFrameに対して、Amazon Bedrockを利用した処理を並列で呼び出す方法 PandasのDataFrameに対して、Amazon Bedrockを利用した処理を並列で呼び出す方法を調べてみました。PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法のAmazon Bedrockバージョンです。こちらも端的にはpandarallelを使いましょう、です。
PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法 PandasのDataFrameに対して、OpenAI APIを利用した処理を並列で呼び出す方法を調べてみました。結論としては、pandarallelを使うのが最も簡単だろうという感じです。
from pandarallel import pandarallel pandarallel.initialize() summary_df["summary"] = summary_df["url"].parallel_apply(get_summary) display(summary_df) 前提条件 openai==1.16.2 pandarallel==1.6.5 事前準備 from __future__ import annotations import openai import urllib import pandas as pd urls = [ "https://www.inoue-kobo.com/llm/openai-reduce-embedding-dim/", "https://www.inoue-kobo.com/aws/selenium-serverless/", "https://www.inoue-kobo.com/aws/aws-service-summary/", "https://www.inoue-kobo.com/ai_ml/duckduckgo-langchain-langsmith/", "https://www.inoue-kobo.com/ai_ml/llamaindex-pdf-gradio/", ] summary_df = pd.DataFrame(urls, columns=["url"]) pd.set_option("display.max_colwidth", None) 単純に apply するだけ def get_summary(url: str) -> str | None: res_web = urllib.request.urlopen(url) # type: ignore content = res_web.read().decode("utf-8") res_openai = openai.chat.completions.create( model="gpt-3.5-turbo", temperature=0, messages=[ { "role": "system", "content": "以下はWebサイトの内容です。HTMLタグを削除した上で、150文字以内で要約してください。", }, {"role": "user", "content": content}, ], ) return res_openai.choices[0].message.content summary_df["summary"] = summary_df["url"].apply(get_summary) display(summary_df) 実行時間は12.3sでした。applyしただけでは並列処理は行われないため、この処理時間が基準になります。
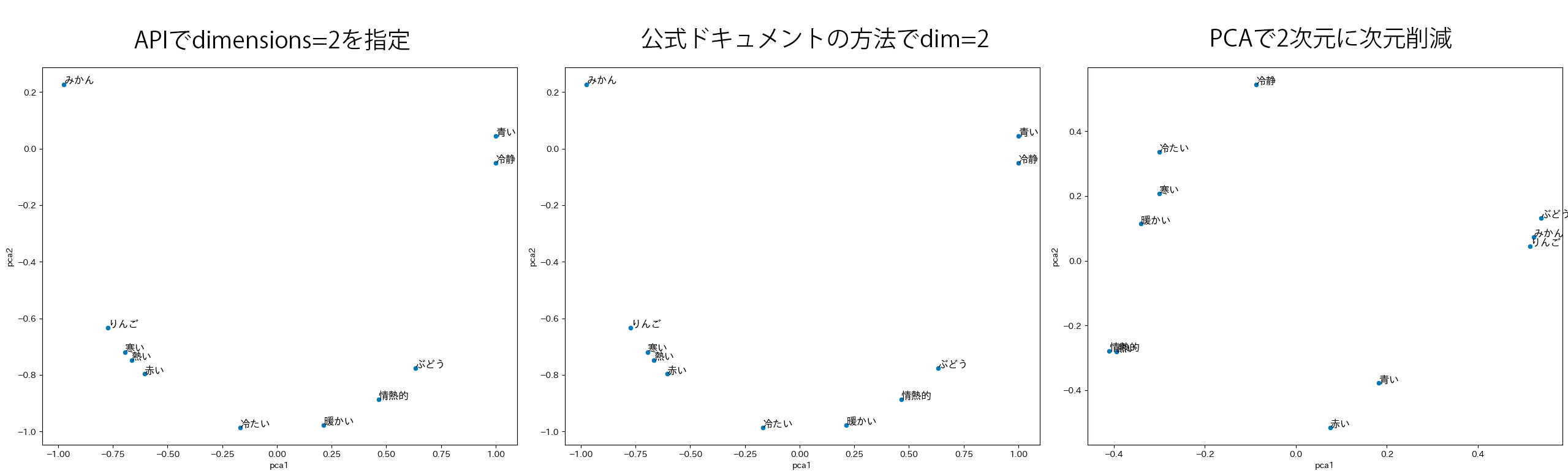
OpenAI API Embeddings の dim 指定の実装方法を確認した OpenAI API として新しくリリースされたベクトル表現取得用モデルである text-embedding-3 では、出力の次元数を指定できるようになりました。どうやってるのかな?と気になったので、実装方法を確認してみました。結論から言うと、以下の公式ドキュメントに書いてある実装方法のショートカットでした(その旨がドキュメントに書いてあります)。
LangChain Evaluation の String Evaluators のまとめ LangChain Evaluation の String Evaluators について、提供されている EvaluatorType の挙動を一通り確認してみました。