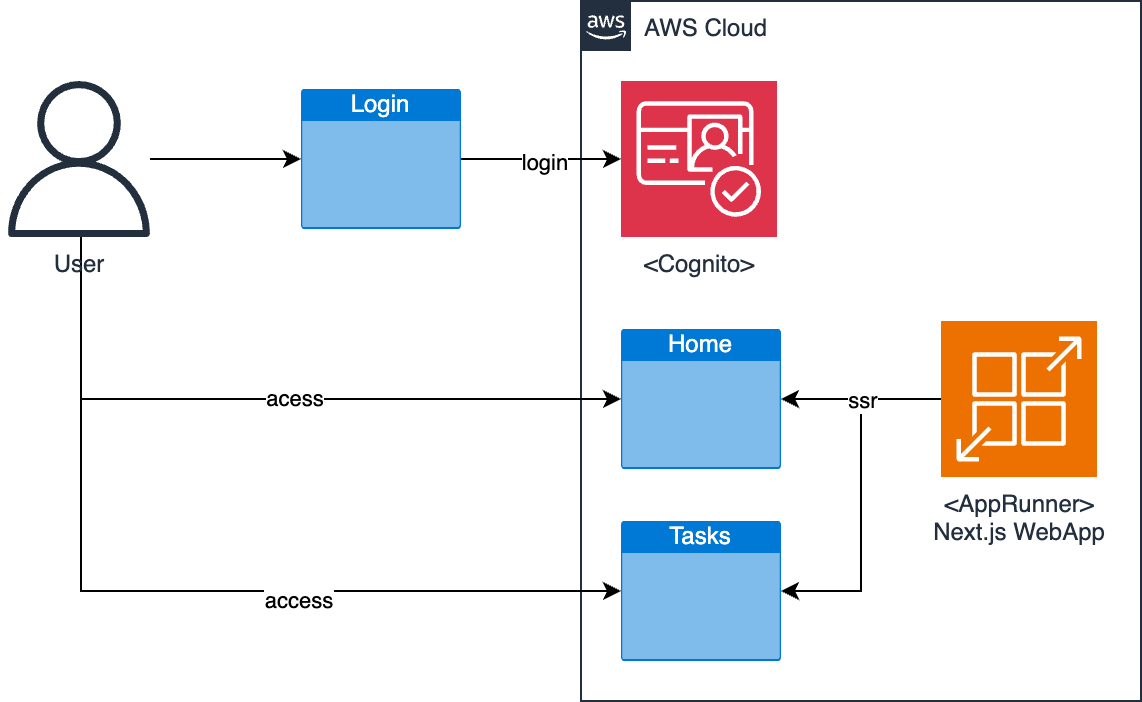
Next.jsで作成したWebアプリをAppRunnerで動かす際のテンプレート Next.jsで作成したWebアプリをAppRunnerで動かす際のテンプレートです。以下の構成を想定しています。
なぜAppRunnerを利用するのか? AWS環境でNext.jsで作成したWebアプリを動かす際にはAWS Amplifyを利用することが多いと思いますが、閉域網などでなるべくシンプルな構成で動かしたい場合には、AppRunnerを利用するのが便利です。本テンプレートはそのような環境でNext.js(で作成したWebアプリ)を動かすための最小限の構成を提供します。
LLMの最新トレンド - 2025年3月 そもそもLLMとは? LLMは Large Language Model の略であり、日本語では大規模言語モデルと表記します。要は言語モデルの大きいものという意味ですが、そもそも言語モデルとは何でしょうか。LLMのトレンドをご紹介する前に、LLMそのものの理解を深めた方がわかりやすいため、簡単にLLMの中身について説明します。
AWS Lambda で Browser Use を動かす AWS Lambda でBrowser Use(browser-use)を動かすためのテンプレートです。利用しているパッケージの容量的に Docker Lambda を利用しています。
業務会社がシステム開発を外注する際の体制と要点 この資料では、業務会社がシステム開発を外注する際の体制と要点について説明しています。
システム開発の全体像 以下は、業務会社がシステム開発を外注する際の全体プロセスと、各登場人物(組織)の役割分担例の例です。各プロセスの役割を明確にし、確実に実行することが重要です。
システムを作らせる技術 エンジニアではないあなたへより。一部追記。
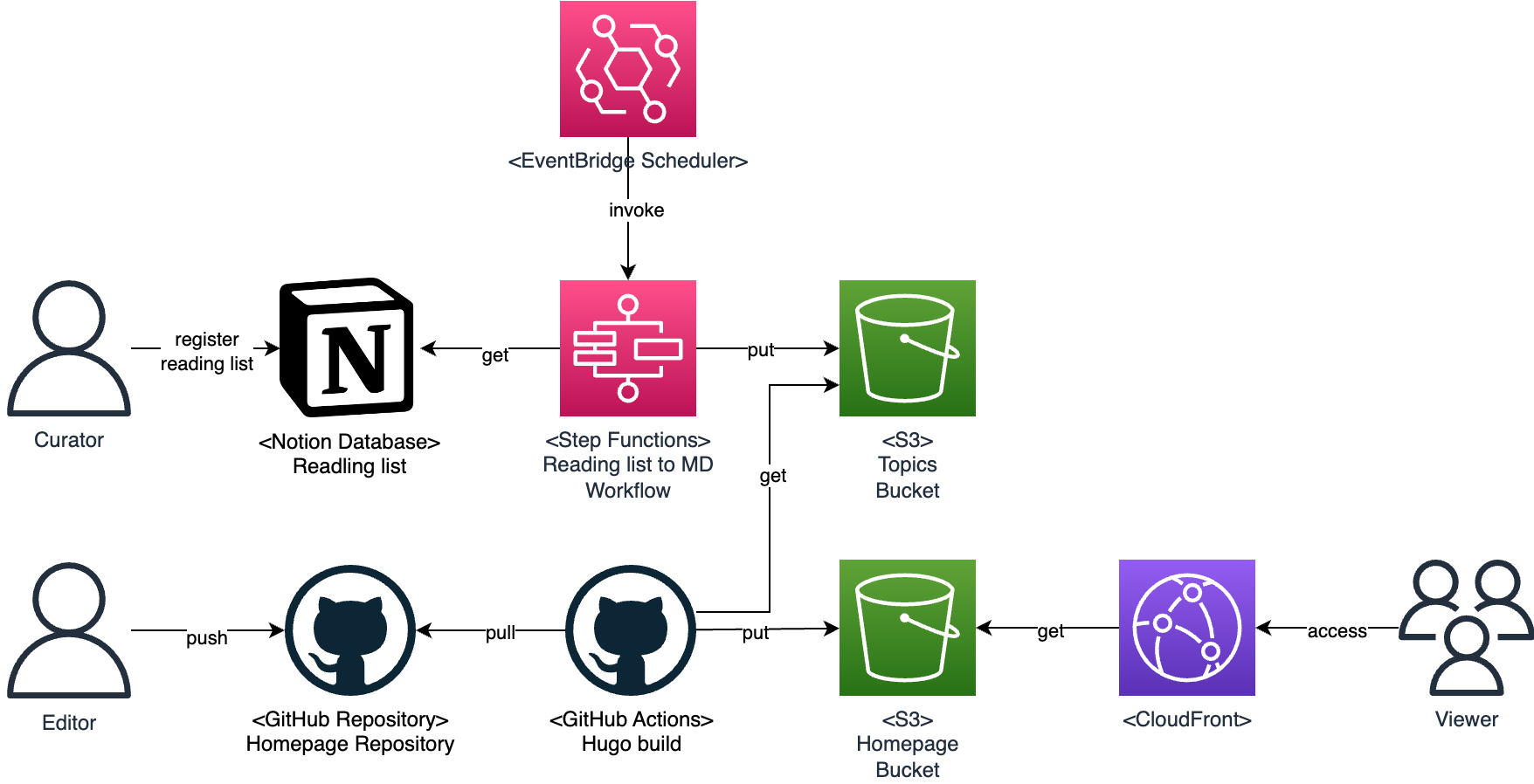
Notion Database で管理しているリーディングリストをホームページに掲載する Notion Database で管理しているリーディングリストを定期的かつ自動的にホームページに掲載する仕組みです。以下の運用を想定しています。
Notion に記録した Web サイトのリーディングリストを Markdown 形式で出力するスクリプト Notion に記録した Web サイトのリーディングリストを Markdown 形式で出力するスクリプトを作成しました。以下のような運用を想定しています。
DifyをAmazon Lightsailで動かす DifyをLightsailで動かす方法です。絶対に失敗しないDifyデプロイの手順、AWS Lightsail編で紹介されているままですが、起動スクリプトを貼り付けるだけでDifyまで起動するようにしているため、必要な操作はLightsailの初期設定のみです。
⚠️ 本手順を実行すると、インターネット上に公開された状態でDifyサービスが動作します。別途、Lightsail のファイアウォールでインスタンストラフィックを制御するなどを参考に、アクセス元を制限するなどのセキュリティは適切に設定してください。また、本手順のみでは平文での通信となるため、あくまで動作確認用としてご利用ください。 Lightsailインスタンスを作成する Amazon Lightsailにて以下のようにインスタンスを作成します。インスタンスのサイズは2GBのものを選択してください。1GBだとメモリ不足で起動しないことがあります。
現在のシステム開発とアジャイル手法 本書では、変化の激しい市場環境に対応する現代のシステム開発手法に焦点を当て、リーンスタートアップ、アジャイル開発について解説します。これらの手法がどのようにしてプロダクトの価値を最大化し、顧客のニーズに応えるかを詳述します。従来型の固定スコープ開発については、別資料を参照してください。
システム開発の進化と現状 プロダクト開発とシステム開発の関係 プロダクトは顧客の課題を解決するための成果物です。プロダクトを構成する要素として、デジタル技術を利用したシステムは非常に重要です。現在のプロダクト開発では、迅速な対応が求められているため、システム開発にも同様のスピード感と柔軟性が必要とされています。
従来型システム開発のプロジェクトマネジメント基礎 本書では、スコープが固定され、予算や納期の達成が重視される従来型のシステム開発に焦点を当て、プロジェクトのプロセス概要とプロジェクトマネージャーの基本的な役割について解説します。新規事業開発や変化の激しい環境で要求されるリーンスタートアップ型のシステム開発については、別資料を参照してください。
プロジェクトマネジメントの基本概念 プロジェクトマネジメントとは プロジェクトマネジメントとは、目標達成のためにプロジェクトを計画、実行、管理する活動です。プロジェクトマネージャは、QCD(品質: Quality、コスト: Cost、納期: Delivery)の観点からリソース割当の優先度を調整し、プロジェクトの目的と成果物の達成に向けてリソースを効果的に配分する役割を果たすことが期待されます。
Notion に記録した議事録をデータベースに変換するスクリプト Notion に記録した議事録をデータベースに変換するスクリプトを作成しました。以下のように普通のページとして Notion に議事録を記録しているとします。