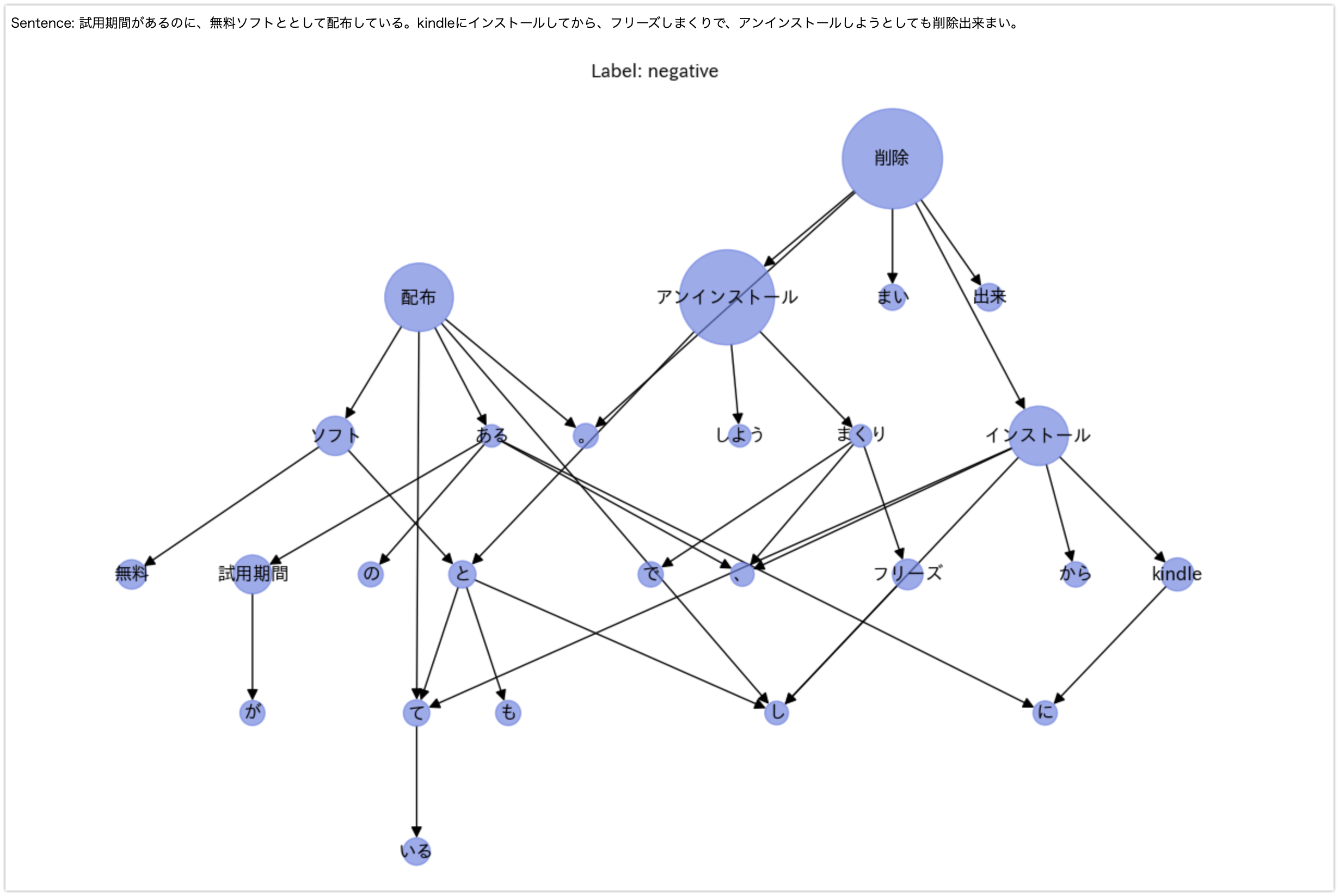
Integrated Gradientsでグラフニューラルネットワークを可視化する TL;DR Integrated Gradients(統合勾配)を利用して、グラフニューラルネットワークによる推論モデルの可視化を行ってみました。よくあるデータセットだと効果が直感的にわかり難いと感じたため、日本語ベンチマーク用データセットであるJGLUEのMARK-jaを利用し、日本語の文を係り受け解析した上でグラフ構造に変換して入力し、Itegrated Gradientsによりどの語句として表現されたノードの反応を可視化してみました。

OpenAI Whisper を使って音声から文書の要約を行ってみる TL;DR 話題のOpenAI - Whisperで文字起こしをやっていました。単純に試すだけなら色々な記事がでているので、音声入力から文書要約までを行ってみました。以下のようなワークフローです。全てGoogle Colab上で実行しています。

Stable Diffusion を GPU なしのローカル PC で動かす TL;DR DALL・E 2やMidjourneyなど、テキストから画像を生成するモデルが話題になっていますが、その中でもStable Diffusionはオープンソースとしてモデルが公開されています。Hugging Face経由で利用ができるため、簡単にローカル PC で動かすことができます。ということで試してみました。
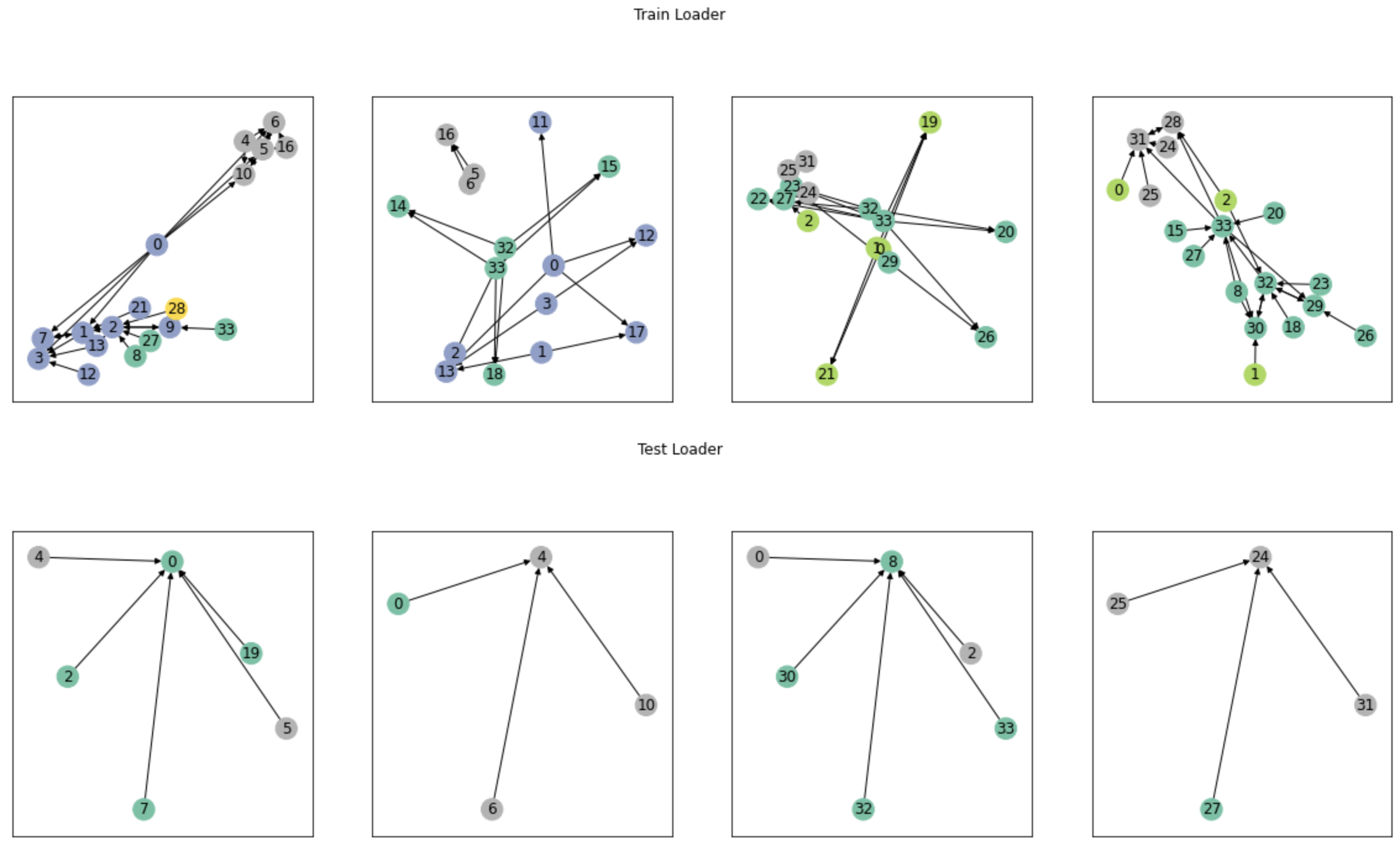
1 つのグラフに対し、PyG の Sampler を利用してMini Batchによる学習を行う TL;DR 大きな構造のグラフをグラフニューラルネットワークで学習する場合、メモリに乗り切らない可能性があるため、サンプリングして学習する必要があります。
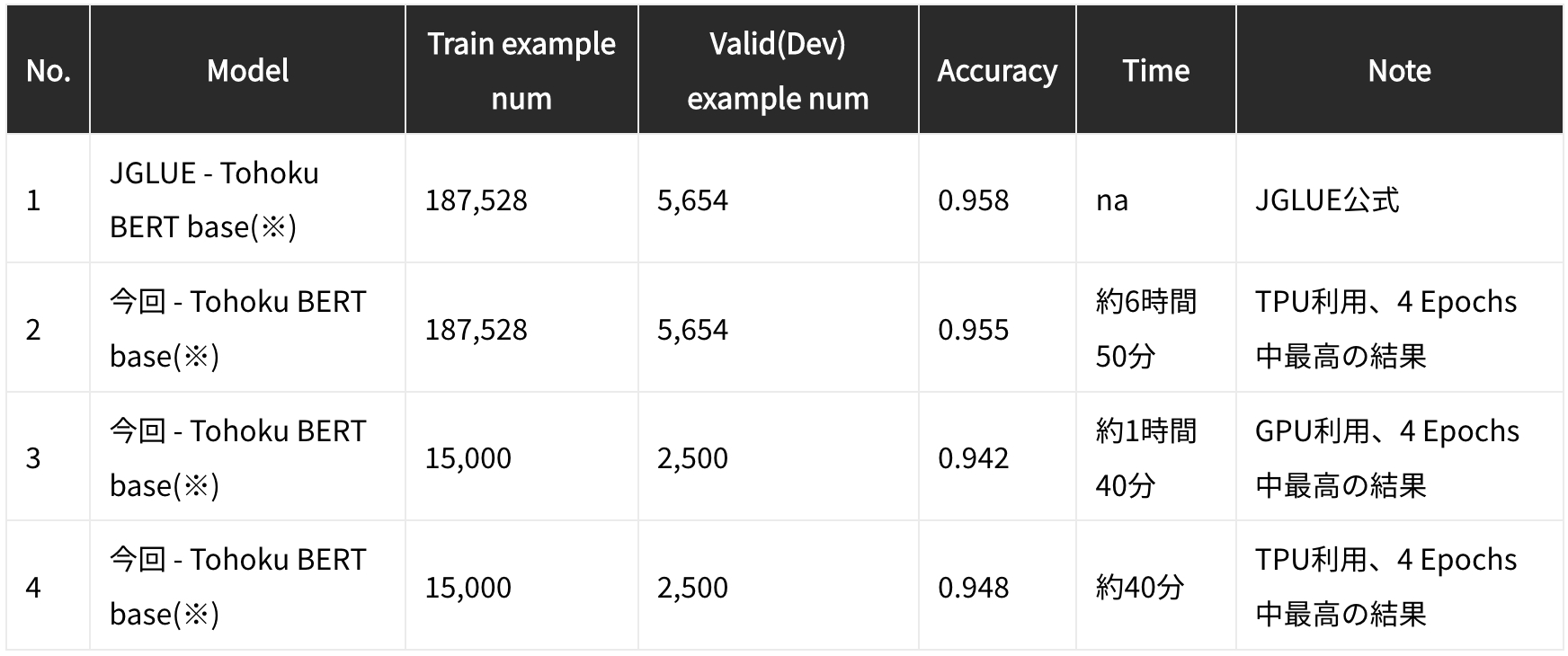
JGLUE/MARC-jaをGoogle Colabで評価してみる TL;DR ヤフー株式会社により、標準的な自然言語処理の標準ベンチマークであるGLUEの日本語版としてJGLUEが公開されています。
今回は日本語の二項分類タスクの評価用データセットであるMARC-jaについて、Google Colab上で実際に評価してみました。モデルはHuggingfaceを利用し、以下に対するファインチューニングを行っています。
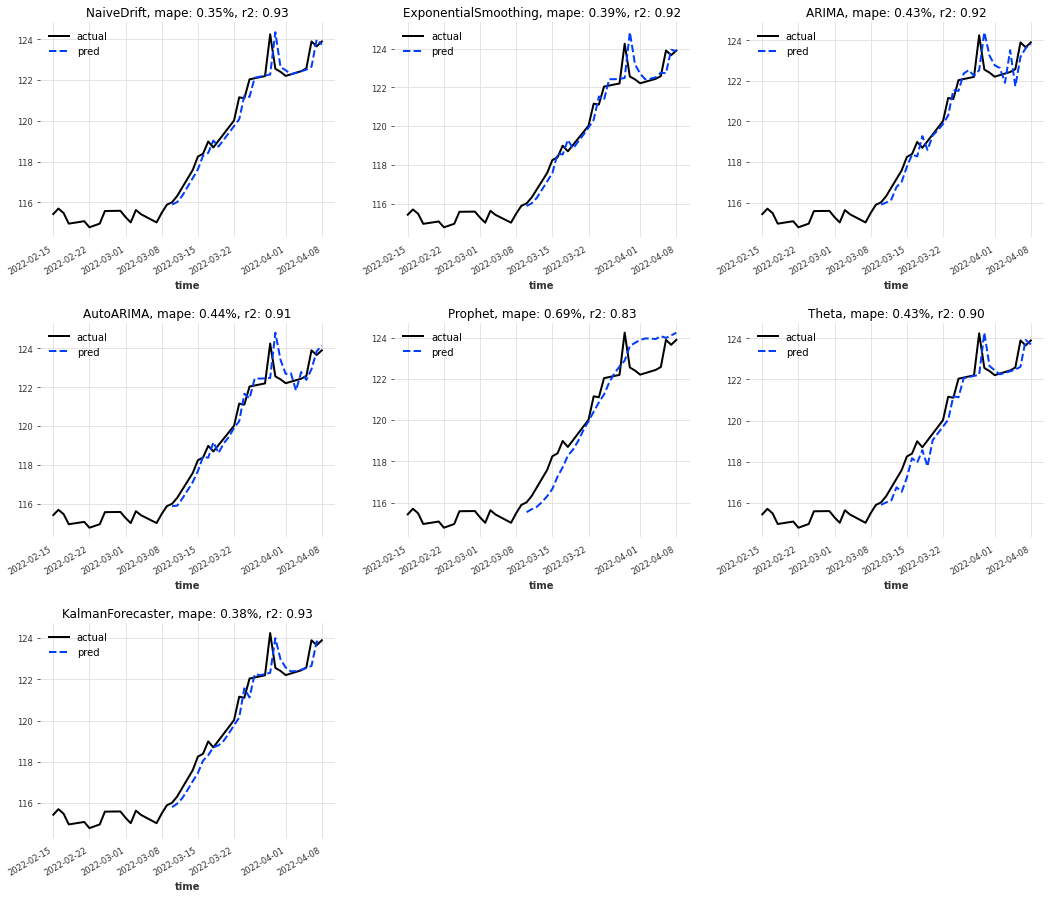
時系列予測用フレームワークであるDatrsでドル円為替を予測してみる TL;DR 最近は円安が進んでいることもあり、ドル円為替レートを例に時系列予測をやってみました。時系列予測フレームワークであるDartsを利用し、複数モデルの同時評価を行っています。
ドル円為替のデータについては、みずほ銀行が提供するヒストリカルデータより日次データを利用しています。
外国為替公示相場ヒストリカルデータ ちなみに、Neural Architecture SearchのDARTSとは全くの別物です。
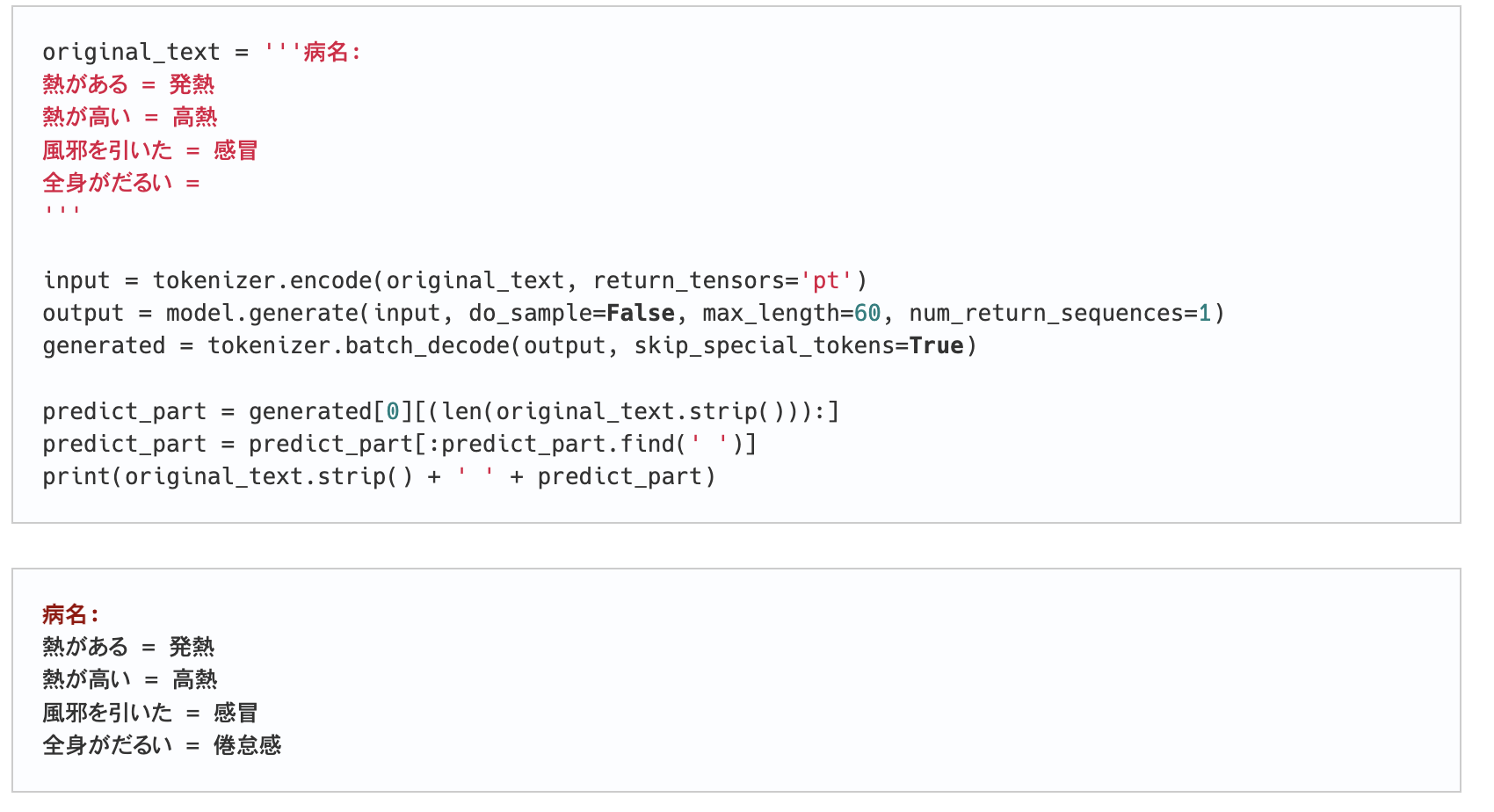
Huggingface Transformersによる日本語GPT-2モデルのrinnaを利用した推論の例 TL;DR Huggingface Transformersにより、日本語GPT-2モデルであるrinnaの公開モデルで以下の推論を行う場合のサンプルです。
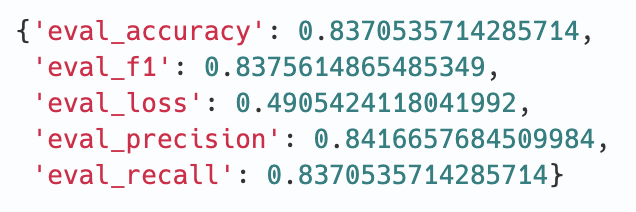
Huggingface TransformersでBERTをFine Tuningしてみる TL;DR 様々な自然言語処理モデルをお手軽に使えるHuggingface Transformersを利用し、日本語の事前学習済みBERTモデルのFine Tuningを試してみました。
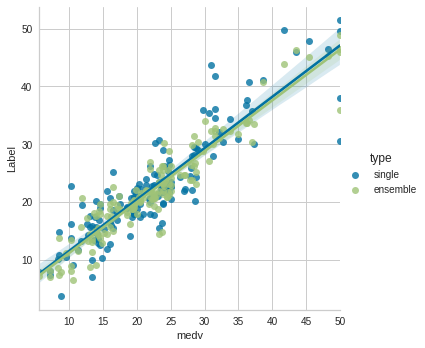
PyCaretで学ぶデータ分析におけるAutoMLの利用 TL;DR ボストン住宅価格データセットを利用して、データ分析におけるAutoMLの利用を解説します。 似たようなコンテンツは他にも色々有りますが、手動でのデータ分析からAutoMLの利用までの一連の流れを説明する機会があったので、その内容を纏めています。 以下のような流れでの解説です。
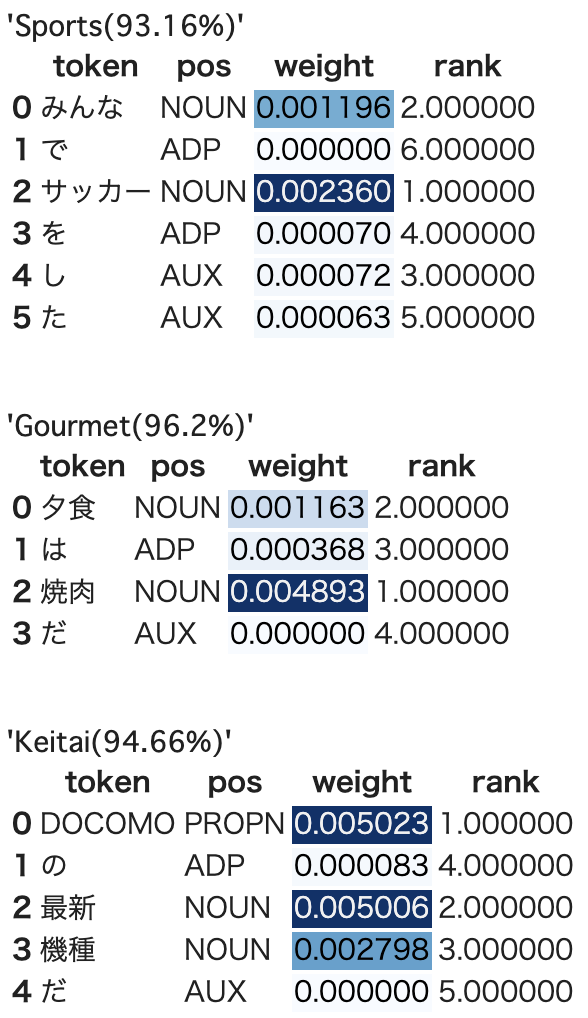
自然言語処理で使われるAttentionのWeightを可視化する(spaCy版) TL;DR 自然言語処理で使われるAtentionのAttention Weight(Attention Weightを加味した入力シーケンス毎の出力)を可視化します。 基本的に自然言語処理で使われるAttentionのWeightを可視化すると同様ですが、spaCyを利用したバージョンです。
